

El basc fent camí en els grans models lingüístics i en els bots
2025/03/01 Leturia Azkarate, Igor - Informatikaria eta ikertzailea Iturria: Elhuyar aldizkaria
Fa ja dos anys que van aparèixer bots capaços de respondre a qualsevol pregunta i realitzar tot tipus de tasques, i des de llavors ChatGPT, Gemini, Copilot, Claude i companyia estan a tot arreu i són molt utilitzats. Aquests instruments es basen en grans models lingüístics i/o LLM (Large Language Models). En aquest article explicarem el camí que està recorrent el basc en aquests models. També explicarem el funcionament dels bots i de les LLM, perquè el basc pugui entendre les dificultats que existeixen per a avançar en ells, però també perquè és important entendre el funcionament de qualsevol tecnologia omnipresent i cada vegada més necessària en molts camps.

Fa gairebé dos anys escrivim en aquest espai l'article titulat El boom de la intel·ligència artificial creativa. I no podem dir que des de llavors l'explosió hagi disminuït la seva influència; per contra, l'ona expansiva del boom s'ha propagat contínuament i a tot arreu. Llavors els sistemes d'Intel·ligència Artificial o AA creatius eren capaços de crear text o imatge; perquè des de llavors hem vist sistemes que generen música (com Suno) i també vídeo (com el Sora d'OpenAI). Han aparegut nombrosos bot nous: Copilot de Microsoft, Claude d'Anthropic, Gemini de Google, Meta AI, Perplexity, Jasper AI... També s'han multiplicat els LLM (Large Language Model) o nous models lingüístics o versions dels anteriors: PaLM, GPT-4, Grok, Gemini, Claude... Així mateix, el panorama ha canviat molt en els LLM de llicència lliure amb l'aparició d'OpenAssistant, Mixtral, Gemma, Qwen i, sobretot, LLaM de Meta.
LLM o Gran Model Lingüístic
No és fàcil seguir el fil d'aquesta sopa de noms i conceptes. Però almenys és convenient i interessant saber què és un LLM, què és un bot i com es desenvolupen.
Es pot dir que des de fa dos o tres anys estem vivint una nova era en les tecnologies de la llengua i de la parla, l'era dels grans models lingüístics o dels LLM. Els LLM són un tipus de xarxa neuronal profunda capaç de respondre correctament a molts problemes que fins ara no havien estat resolts (creació automàtica de textos, resposta a preguntes de qualsevol tipus, redacció de programes informàtics...) i de fer moltes tasques que ja es realitzaven amb altres tipus de xarxes neuronals profundes (traducció automàtica, resum automàtic...). En definitiva, qualsevol treball en text es pot realitzar en l'actualitat (i en molts casos es fa) a través de LLM.
Els LLM són xarxes neuronals profundes, tipus transformador, en la seva majoria de classe de decoder simple. Però més enllà de l'estructura, tenen moltes altres característiques importants. D'una banda, es tracta de xarxes gegantesques que tenen molts nodes d'entrada i moltes capes intermèdies amb molts nodes; els enllaços o paràmetres que la xarxa ha d'aprendre són milers de milions. D'altra banda, s'entrenen amb textos buits, però amb un gran nombre de textos, fins a milions de paraules. Finalment, solen ser plurilingües, és a dir, s'entrenen amb textos de diferents idiomes i funcionen en tots ells (encara que millor en alguns casos que en uns altres, com es veurà més tard).
La missió de LLM és, en principi, una cosa única i molt simple: donar una seqüència de paraules i predir la següent paraula més probable a partir de les seqüències de paraules que ha vist durant l'entrenament. És a dir, si en l'entrada li donem la sèrie “catorze nous remotes”, ell hauria de traduir-la “acostar-la”. I això és l'única cosa que fa un LLM. El que passa és que si li donem a “acostar-nos catorze nous remotes, i” retornarà “i”, si ho fem de nou “quatre”… I així, a través d'aquest procés d'acte-regressió podem posar en producció textos o respostes llargues. A més, com s'ha dit, poden tenir molts nodes a l'entrada, fins i tot alguns milers, la qual cosa permet que els textos o peticions d'entrada (els “prompt”, utilitzant el terme de l'àrea) siguin molt llargs i complexos.
En realitat, els LLM no funcionen amb paraules, sinó amb números. I com per a expressar totes les paraules de molts idiomes es necessiten massa números, treballen amb les paraules que es diuen “token”. Però per a facilitar les explicacions, direm que prenen les paraules.
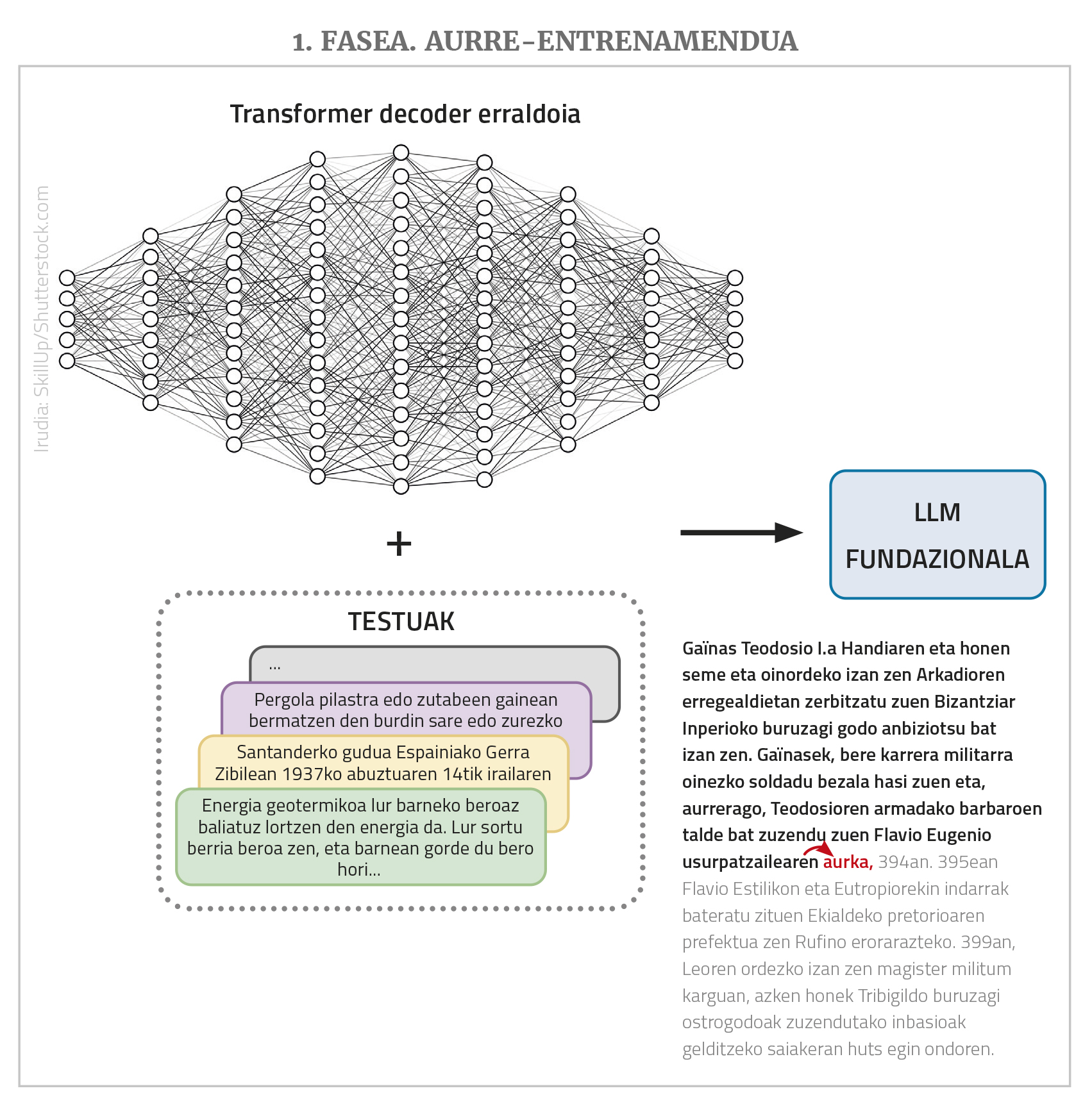
Per tant, resumint, un LLM és una xarxa neuronal gegant tipus transformador (normalment de classe decoder) que, amb un text extens, preveu la següent paraula, i per a això s'ha entrenat prèviament amb molts textos de diferents idiomes (més endavant veurem per què “avanci”-----------). Els LLM que es troben en aquesta situació bàsica també reben altres noms: model fundacional, GPT (Generative Pre-Trained Transformer), model lingüístic autoregresivo... A causa de les grans dimensions de la xarxa i de la col·lecció d'entrenaments, els textos que genera són normalment lingüísticament correctes, adequats als nivells de morfologia, sintaxi i semàntica, mostrant un gran coneixement del món i altres capacitats en general.
De LLM a bot
Un bot com ChatGPT o Gemini es basa en un LLM d'aquest tipus, però encara necessita dos passos d'entrenament: un ajust fi d'instruccions i una alineació amb les preferències humanes.
Un LLM, com s'ha esmentat anteriorment, dona continuïtat a un text que se li dona en la introducció. Però als bots se'ls donen preguntes o peticions per a fer una tasca. Davant aquesta mena de situacions, és possible que el LLM respongui correctament si en els textos d'entrenament ha vist respostes de preguntes o peticions similars. Però en els corpus d'entrenament no sol haver-hi molt. Per això, per a un millor acompliment del treball de bot el LLM necessita una nova fase d'entrenament denominada ajust fi d'instruccions (instruction fini-tuning en anglès). Aquest entrenament consisteix en l'elaboració d'una col·lecció d'instruccions per als diferents tipus de tasques que es desitgen realitzar, això és, exemples de parells de solucions de comanda: preguntes amb respostes, sol·licituds de resums amb resums, sol·licituds de correcció de textos incorrectes amb les correccions oportunes, sol·licituds de traducció amb traducció, sol·licituds de creació de textos amb text, etc. D'aquesta manera, la MPR aprèn a donar una resposta adequada a aquesta mena de demandes.
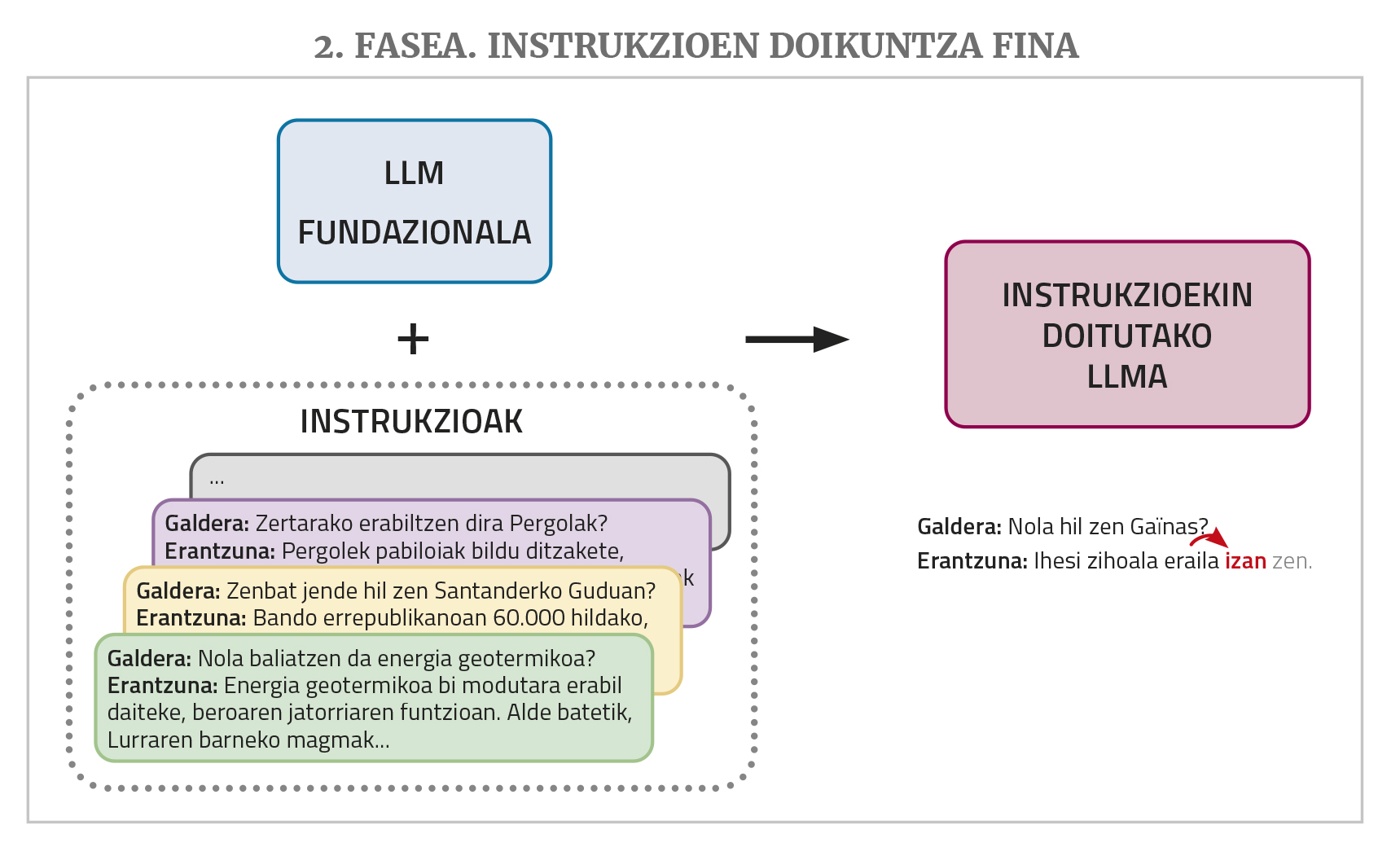
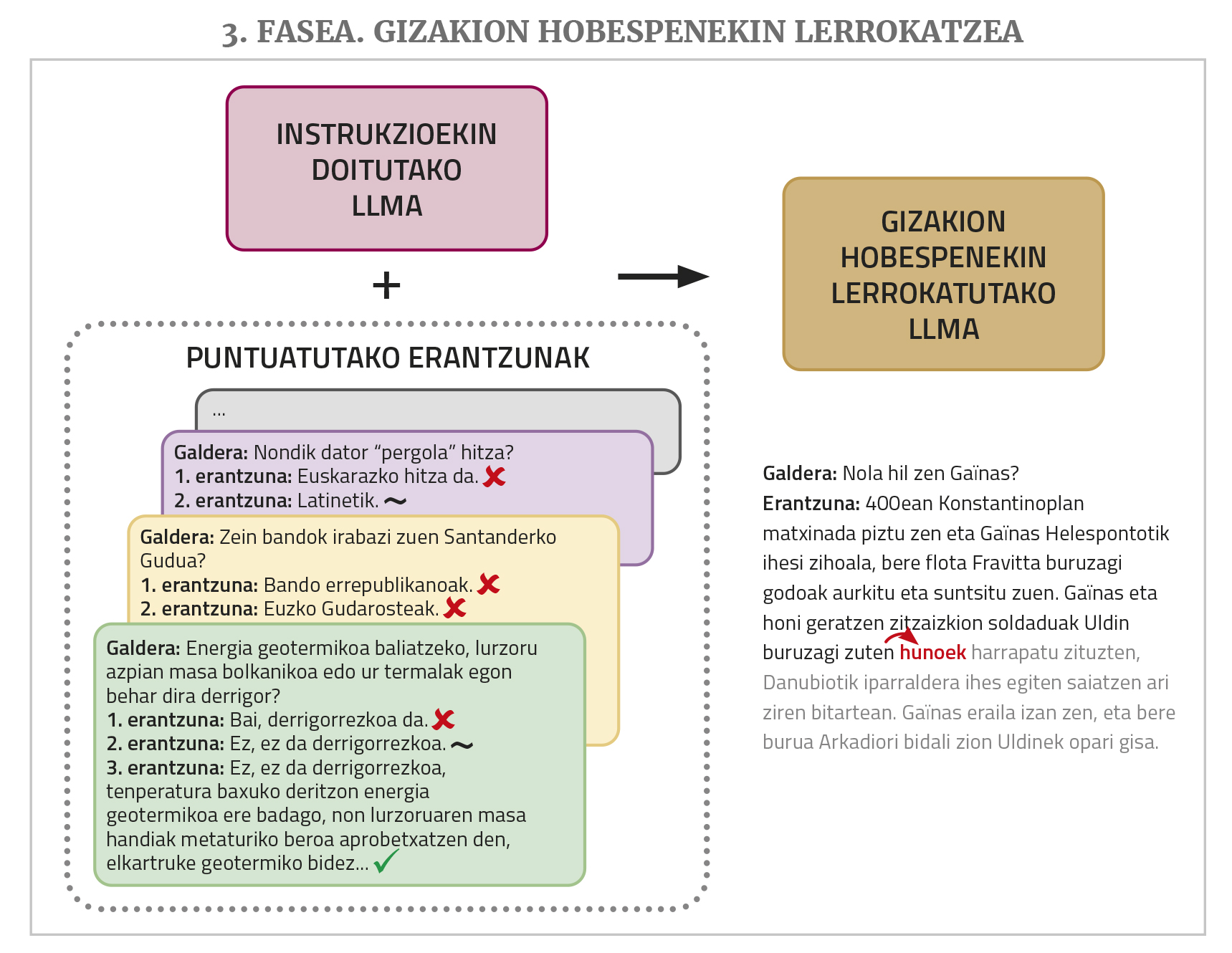
Finalment, per a un millor funcionament es requereix una fase d'entrenament denominada alineació amb preferències d'éssers humans (alignment with human preferences, en anglès). Es demana a la MPR que faci diverses tasques sol·licitant per a cadascuna d'elles més d'una possible resposta i després diverses persones avaluen aquestes respostes. Aquestes respostes puntuades s'utilitzen en aquest últim entrenament, la qual cosa permet que les respostes dels bots s'ajustin millor (“alinear”, utilitzant el terme de l'àrea) a les desitjos o a la lògica dels éssers humans. Per a realitzar aquest pas existeixen diferents tècniques com l'aprenentatge de reforç mitjançant realimentació humana (en anglès, Reinforcement Learning from Human Feedback o RLHF) o l'optimització de les prioritats directes (en anglès, Direct Preference Optimization o DPO).
Construcció de LLM propis en basc
Més amunt hem comentat que els LLM o els bots són multilingües, ja que generalment s'entrenen amb textos de diferents idiomes. Però no funcionen igual per a tots els idiomes, ja que el nombre de textos que es veuen en l'entrenament no és el mateix: la majoria dels textos són en anglès, els d'altres idiomes (fins i tot els d'altres idiomes principals) són molt menys, i no diguem els dels idiomes petits. No obstant això, malgrat aquestes diferències, un LLM pot arribar a aprendre tots els idiomes bastant ben a causa de la propietat d'aprenentatge per transferència (transfer learning, en anglès). S'ha demostrat que les xarxes neuronals ja tenen aquesta propietat i, d'alguna manera, aprofiten els coneixements adquirits en un domini o en una o diverses llengües per a poder aprendre un altre domini o idioma amb menys dades; en el cas de les llengües, a més, es necessiten menys dades si ja domina una llengua de la mateixa família (en certa manera ocorre de manera similar amb els éssers humans). Així, encara que en l'article anterior afirmàvem que el ChatGPT parlava en basc bastant bé, però que encara tenia molt a millorar, en passar de GPT 3.5 a GPT 4, hi ha hagut una millora notable, i cal reconèixer que ho fa molt bé en basc.
Encara que això sigui així, per diverses raons (sobirania tecnològica, que el futur de la nostra llengua no estigui en mans de les multinacionals nord-americanes, pèrdua de privacitat que suposa l'ús de les eines dels gegants tecnològics...), és convenient desenvolupar el LLM o els bots en basc, i en això estem treballant diverses organitzacions del País Basc.
Construir un LLM en basc des de zero, no obstant això, no és tasca fàcil. Perquè funcionin bé, cal entrenar amb milions de paraules, i en basca no hi ha tantes. El nombre de textos que es pot aconseguir amb la traducció automàtica és suficient, i amb això també hem realitzat proves pilot, però els resultats no han estat suficients. A més, l'entrenament complet d'aquestes gegantesques xarxes requereix màquines molt potents i triga moltíssim. Per això, és molt car i, per tant, inviable.
Per això, la via que habitualment s'utilitza és la d'adoptar un LLM fundacional lliure, prèviament entrenat, i realitzar un ajust fi o un fini-tuning perquè pugui aprendre millor basc. En definitiva, aquest ajust suposa continuar amb l'entrenament a través de textos en basc, per la qual cosa també se'l denomina pre-entrenament continuat o continual pre-training. Es tracta que el LLM que s'ha pre-entrenat ja sap que té altres idiomes, que té un coneixement general i altres competències, i que gràcies a l'aprenentatge per transferència no necessita tant de temps de text o entrenament per a aprendre basc. A més, si es desitja, es poden utilitzar tècniques com LoRA (Low-Rank Adaptation) per a substituir tota la xarxa d'una banda, reduint considerablement les exigències de memòria.
En els últims treballs en aquest camí s'utilitza Flama desenvolupat per l'empresa Meta i que ha estat cedida en llicència lliure. El centre HiTZ de la UPV/EHU, per exemple, prenent com a base Flama 2 i seguint un entrenament amb la col·lecció de textos EusCrawl, va treure al gener de l'any passat el LCM en basc Latxa, que posteriorment, a l'abril, va adaptar i va millorar amb un corpus de text major. Latxa va obtenir millors resultats que qualsevol altre LLM en les proves de competència en basca (avaluat amb proves preliminars d'EGA) i en les preguntes o tasques generals només superava a GPT 4 (amb conjunts d'avaluació preparats per a preguntes generals, de comprensió lectora i de preguntes d'oposicions).
En el nostre centre de Tecnologies Orai NLP d'Elhuyar, vam agafar la LLLaMa 3.1 i l'ajustem amb el corpus Zelai (Handi Orai Orai és la major col·lecció de textos lliures en basc recopilats per Zelai Orai, amb 521 milions de paraules), i el resultat és el de lliure -eus-8B, presentat al setembre de l'any passat. Ha obtingut els millors resultats en tots els tipus de tasques entre els models fundacionals en basc lleugers (menys de 10 mil milions de paràmetres), i fins i tot ofereix millors resultats en algunes tasques que els models molt més grans.
I els bots en basc?
A la vista d'aquests resultats, un pot pensar que ja tenim una espècie de ChatGPT en basca que hem creat aquí. Però com hem vist, els resultats que obtenen els models locals per a molts tipus de sol·licituds de tasques en basca encara no aconsegueixen el nivell de GPT4, i sobretot, els resultats són sensiblement inferiors als que s'obtenen amb l'anglès.
La raó d'això l'hem explicat a dalt: L'obtenció d'un bot funcional des d'un LLM requereix també un ajust fi d'instruccions i fases d'entrenament per a alinear-lo amb les preferències humanes. S'ha observat que una de les principals causes del bon rendiment dels bot comercials són les sèries de dades utilitzades en aquests dos passos, molt grans i de qualitat. I aquest tipus de dades (conjunts de solucions de comanda i qüestionaris de resposta avaluats per les persones), a diferència dels textos que es poden obtenir de la xarxa de pre-entrenament en quantitats relativament elevades de manera automàtica, exigeixen ser generats manualment per les persones, la qual cosa resulta molt costós. Els gegants tecnològics li assignen molts diners i mà d'obra, i aquests paquets de dades no els deixen solts. No hi ha recursos suficients per a crear aquest tipus de coses en basca. Existeixen alguns conjunts de dades lliures d'aquest tipus, però no són prou grans, no estan en basc, ... Fins i tot sense un ajust d'instruccions fi es pot aconseguir que unes certes tasques es facin millor amb un o diversos exemples de la tasca que es vol realitzar en la pròpia pregunta (aquesta tècnica es denomina prompt engineering o in-context learning), però els resultats no són iguals als que s'obtenen amb l'ajust.
Per tot això, encara queda molta feina per fer per a tenir el nostre propi bot funcional. Això no vol dir que no ho fem. En el centre Orai, per exemple, tenim diversos treballs en marxa. Per exemple, més enllà del coneixement del basc i de la resposta a les demandes generals en basca, hem analitzat si els LLM i els bots tenen coneixement d'Euskal Herria i de la cultura basca, creant i facilitant una sèrie de dades per a avaluar-ho. El conjunt de dades està en anglès (al cap i a la fi, els xats de grans empreses funcionen millor en anglès i es volia avaluar el coneixement dels seus temes bascos, no la competència en basca) i s'han fet preguntes en anglès als bot. La conclusió és que tenen un fort biaix cultural i només s'encerten de mitjana al voltant del 20% de les preguntes dels temes bascos. Provant diferents tècniques en models fundacionals lliures, hem intentat millorar-ho i les sessions han estat reeixides, amb una taxa d'encert que ha augmentat entorn del 80%. El centre HiTZ també ha fet un treball similar i una avaluació.
En el centre Orai també treballem el biaix dels LLM en basc. Hem traduït al basc i adaptat al context basc el conjunt de dades BBQ que s'utilitza per a mesurar els biaixos de la LLM, i l'hem fet públic amb la llicència lliure BasqBBQ. S'han mesurat els biaixos dels LLM en basc (Latxa i Flama-eus-8b) i s'han comparat amb els del model Flama original que els sustenten. I s'ha vist que els models adaptats al basc no tenen major biaix, sinó tot el contrari.

Finalment, també hem realitzat els primers experiments sobre el refinat ajust de les instruccions i la seva alineació amb les preferències humanes. Per a això s'han obtingut una sèrie de conjunts de dades en anglès lliurement disponibles, tant d'instruccions (tipus de solucions de comanda) com de respostes puntuades, i una vegada traduïdes al basc mitjançant traducció automàtica, s'han procedit a passar aquestes altres dues fases d'entrenament al nostre model fundacional LLLaMa-eus-8B. Així, hem construït el primer bot en basc que ha passat per totes les fases d'entrenament. I hem comparat els resultats amb el model de xat Flama de grandària similar que Meta va treure amb les seves dades privades, ajustat a les instruccions i alineat amb les preferències humanes, i hem vist que el nostre funciona molt millor en aquestes tasques creatives en basca. No obstant això, la qualitat dels resultats encara no arriba al model més tancat com ChatGPT. Al cap i a la fi, com ja s'ha dit, els conjunts de dades obertes d'instrucció i entrenament de DPO no són tan grans com els dels gegants tecnològics, i a més, el fet que hagin estat traduïts per traducció automàtica també té una certa influència.
Tots aquests treballs, i molts més, hauran de ser realitzats encara perquè es converteixi en un dels bot funcionals més utilitzats en basc. Però, fins i tot quan s'aconsegueix, pot ser un problema posar-lo a la disposició de la societat basca. De fet, entrenar a aquestes gegantesques xarxes neuronals és tan car com fer-ho, tenir en marxa per a poder utilitzar-les també és molt car, ja que necessiten màquines molt potents. Els gegants tecnològics estatunidencs que ofereixen els xats comercials més reeixits estan perdent una enorme quantitat de diners per estar en l'avantguarda d'aquesta revolució i per guanyar quota de mercat. Aquests models no són rendibles i, d'altra banda, l'impacte ambiental d'aquesta mena de màquines grans també és aquí. Per això, l'optimització és tan important com millorar els resultats de tots aquests bots, és a dir, obtenir els mateixos resultats utilitzant xarxes neuronals més sostenibles econòmica i ecològicament.
I precisament per aquest camí va la LLM de codi obert de l'empresa xinesa DeepSeek, coneguda a la fi de gener com DeepSeek-V3. Les descàrregues de l'APP per al seu ús van superar les de ChatGPT als Estats Units, ja que oferia resultats comparables amb les seves a un preu molt més barat. Això va provocar un terratrèmol en les cotitzacions borsàries de les empreses estatunidenques AA i xip i en les expectatives i expectatives de futur. Però a més de la gran qualitat dels resultats, el fet és que, obligats per l'embargament dels xips que la Xina ha posat a la disposició dels Estats Units, les LLM han hagut de buscar vies per a poder desenvolupar-se en xips menys potents.
Aprofitant algunes variants que fins ara no han estat utilitzades pels altres en l'estructura i entrenament de la LLM, l'empresa afirma que el cost de l'entrenament de DeepSeek-V3 ha estat del 6% del GPT-4 i que només ha requerit el 10% de l'energia de l'entrenament de LLLaMa 3.1. El cost d'oferir el model com a servei és molt menor, per la qual cosa es diu que és l'únic que no perd diners, encara que s'ofereix més barat. És a dir, els resultats de DeepSeek són similars als models més tancats com ChatGPT, millors que els de codi obert com LLaMa, és de codi obert i té menys de la desena part de la necessitat energètica (i per tant de cost) dels altres models. Aviat es veurà si es confirma la idoneïtat d'aquest camí, si els desenvolupadors d'altres models també el prenen, i també ens serveix per a desenvolupar i oferir models propis en basc d'una manera més ràpida i econòmica.
