

El euskera haciendo camino en los grandes modelos lingüísticos y en los chatbots
2025/03/01 Leturia Azkarate, Igor - Informatikaria eta ikertzailea Iturria: Elhuyar aldizkaria
Hace ya dos años que aparecieron chatbots capaces de responder a cualquier pregunta y realizar todo tipo de tareas, y desde entonces ChatGPT, Gemini, Copilot, Claude y compañía están en todas partes y son muy utilizados. Estos instrumentos se basan en grandes modelos lingüísticos y/o LLM (Large Language Models). En este artículo explicaremos el camino que está recorriendo el euskera en estos modelos. También explicaremos el funcionamiento de los chatbots y de las LLM, para que el euskera pueda entender las dificultades que existen para avanzar en ellos, pero también porque es importante entender el funcionamiento de cualquier tecnología omnipresente y cada vez más necesaria en muchos campos.

Hace casi dos años escribimos en este espacio el artículo titulado El boom de la inteligencia artificial creativa. Y no podemos decir que desde entonces la explosión haya disminuido su influencia; por el contrario, la onda expansiva del boom se ha propagado continuamente y en todas partes. Entonces los sistemas de Inteligencia Artificial o AA creativos eran capaces de crear texto o imagen; pues desde entonces hemos visto sistemas que generan música (como Suno) y también vídeo (como el Sora de OpenAI). Han aparecido numerosos chatbot nuevos: Copilot de Microsoft, Claude de Anthropic, Gemini de Google, Meta AI, Perplexity, Jasper AI... También se han multiplicado los LLM (Large Language Model) o nuevos modelos lingüísticos o versiones de los anteriores: PaLM, GPT-4, Grok, Gemini, Claude... Asimismo, el panorama ha cambiado mucho en los LLM de licencia libre con la aparición de OpenAssistant, Mixtral, Gemma, Qwen y, sobre todo, LLaM de Meta.
LLM o Gran Modelo Lingüístico
No es fácil seguir el hilo de esta sopa de nombres y conceptos. Pero al menos es conveniente e interesante saber qué es un LLM, qué es un chatbot y cómo se desarrollan.
Se puede decir que desde hace dos o tres años estamos viviendo una nueva era en las tecnologías de la lengua y del habla, la era de los grandes modelos lingüísticos o de los LLM. Los LLM son un tipo de red neuronal profunda capaz de responder correctamente a muchos problemas que hasta ahora no habían sido resueltos (creación automática de textos, respuesta a preguntas de cualquier tipo, redacción de programas informáticos...) y de realizar muchas tareas que ya se realizaban con otros tipos de redes neuronales profundas (traducción automática, resumen automático...). En definitiva, cualquier trabajo en texto se puede realizar en la actualidad (y en muchos casos se hace) a través de LLM.
Los LLM son redes neuronales profundas, tipo transformador, en su mayoría de clase de decoder simple. Pero más allá de la estructura, tienen otras muchas características importantes. Por un lado, se trata de redes gigantescas que tienen muchos nodos de entrada y muchas capas intermedias con muchos nodos; los enlaces o parámetros que la red debe aprender son miles de millones. Por otro lado, se entrenan con textos vacíos, pero con un gran número de textos, hasta millones de palabras. Por último, suelen ser plurilingües, es decir, se entrenan con textos de diferentes idiomas y funcionan en todos ellos (aunque mejor en algunos casos que en otros, como se verá más tarde).
La misión de LLM es, en principio, una cosa única y muy simple: dar una secuencia de palabras y predecir la siguiente palabra más probable a partir de las secuencias de palabras que ha visto durante el entrenamiento. Es decir, si en la entrada le damos la serie “catorce nueces remotas”, él debería traducirla “acercarla”. Y eso es lo único que hace un LLM. Lo que pasa es que si le damos a “acercarnos catorce nueces remotas, y” devolverá “y”, si lo hacemos de nuevo “cuatro”… Y así, a través de este proceso de auto-regresión podemos poner en producción textos o respuestas largas. Además, como se ha dicho, pueden tener muchos nodos a la entrada, incluso algunos miles, lo que permite que los textos o peticiones de entrada (los “prompt”, utilizando el término del área) sean muy largos y complejos.
En realidad, los LLM no funcionan con palabras, sino con números. Y como para expresar todas las palabras de muchos idiomas se necesitan demasiados números, trabajan con las palabras que se llaman “token”. Pero para facilitar las explicaciones, diremos que toman las palabras.
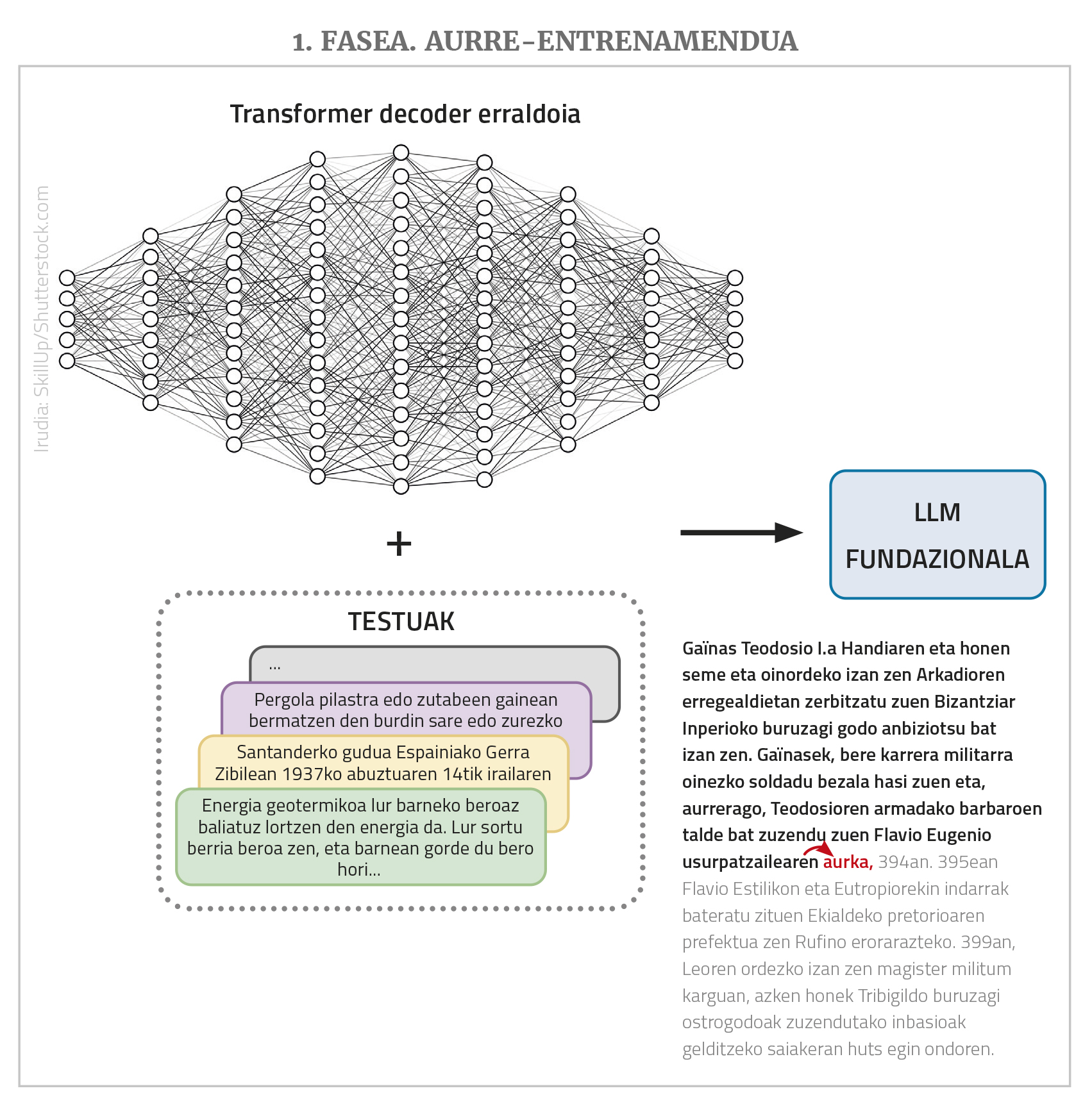
Por lo tanto, resumiendo, un LLM es una red neuronal gigante tipo transformador (normalmente de clase decoder) que, con un texto extenso, prevé la siguiente palabra, y para ello se ha entrenado previamente con muchos textos de diferentes idiomas (más adelante veremos por qué “adelante”-----------). Los LLM que se encuentran en esta situación básica también reciben otros nombres: modelo fundacional, GPT (Generative Pre-Trained Transformer), modelo lingüístico autoregresivo... Debido a las grandes dimensiones de la red y de la colección de entrenamientos, los textos que genera son normalmente lingüísticamente correctos, adecuados a los niveles de morfología, sintaxis y semántica, mostrando un gran conocimiento del mundo y otras capacidades en general.
De LLM a chatbot
Un chatbot como ChatGPT o Gemini se basa en un LLM de este tipo, pero todavía necesita dos pasos de entrenamiento: un ajuste fino de instrucciones y una alineación con las preferencias humanas.
Un LLM, como se ha mencionado anteriormente, da continuidad a un texto que se le da en la introducción. Pero a los chatbots se les dan preguntas o peticiones para hacer una tarea. Ante este tipo de situaciones, es posible que el LLM responda correctamente si en los textos de entrenamiento ha visto respuestas de preguntas o peticiones similares. Pero en los corpus de entrenamiento no suele haber mucho. Por ello, para un mejor desempeño del trabajo de chatbot el LLM necesita una nueva fase de entrenamiento denominada ajuste fino de instrucciones (instruction fine-tuning en inglés). Este entrenamiento consiste en la elaboración de una colección de instrucciones para los diferentes tipos de tareas que se desean realizar, esto es, ejemplos de pares de soluciones de pedido: preguntas con respuestas, solicitudes de resúmenes con resúmenes, solicitudes de corrección de textos incorrectos con las correcciones oportunas, solicitudes de traducción con traducción, solicitudes de creación de textos con texto, etc. De esta manera, la MPR aprende a dar una respuesta adecuada a este tipo de demandas.
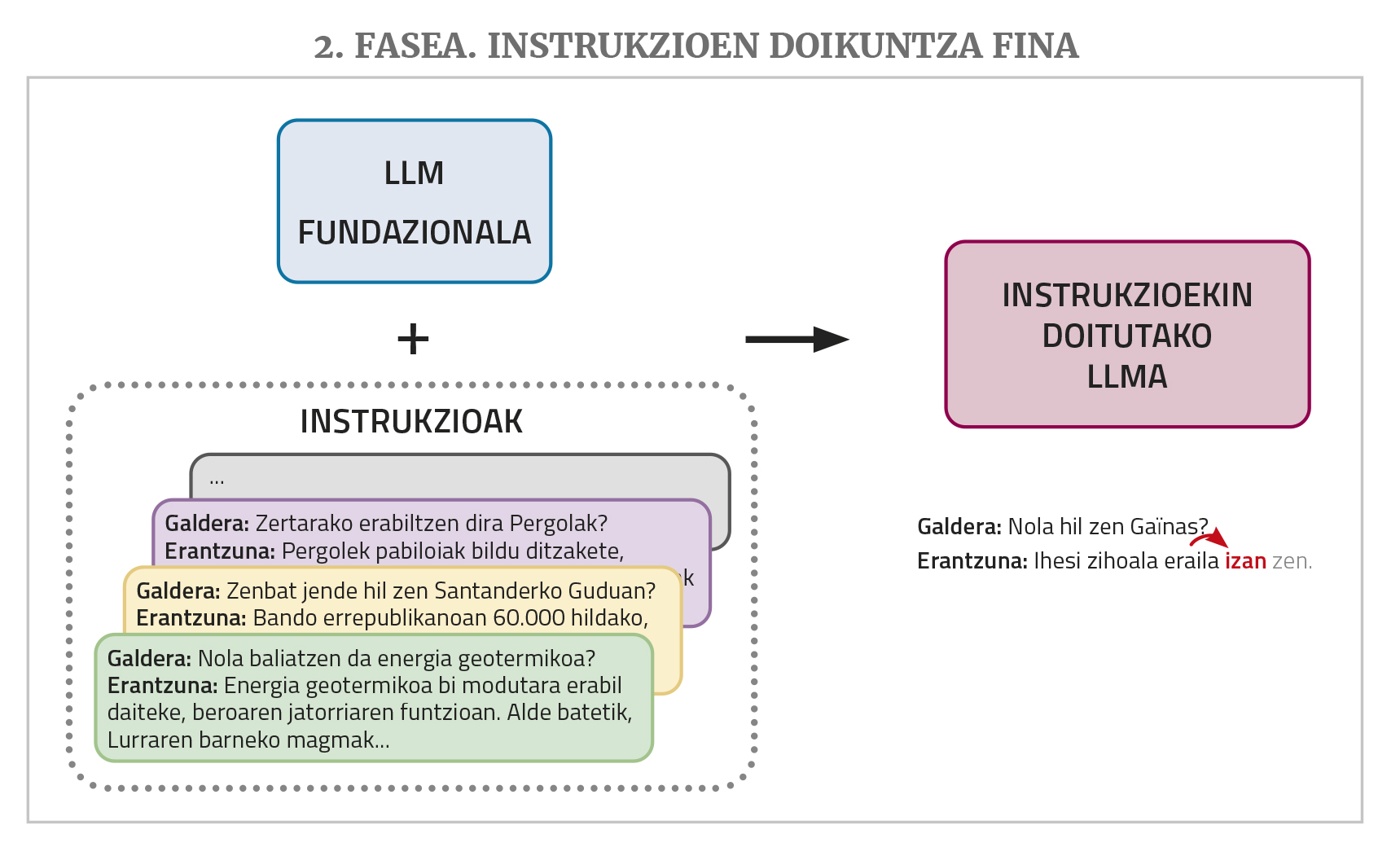
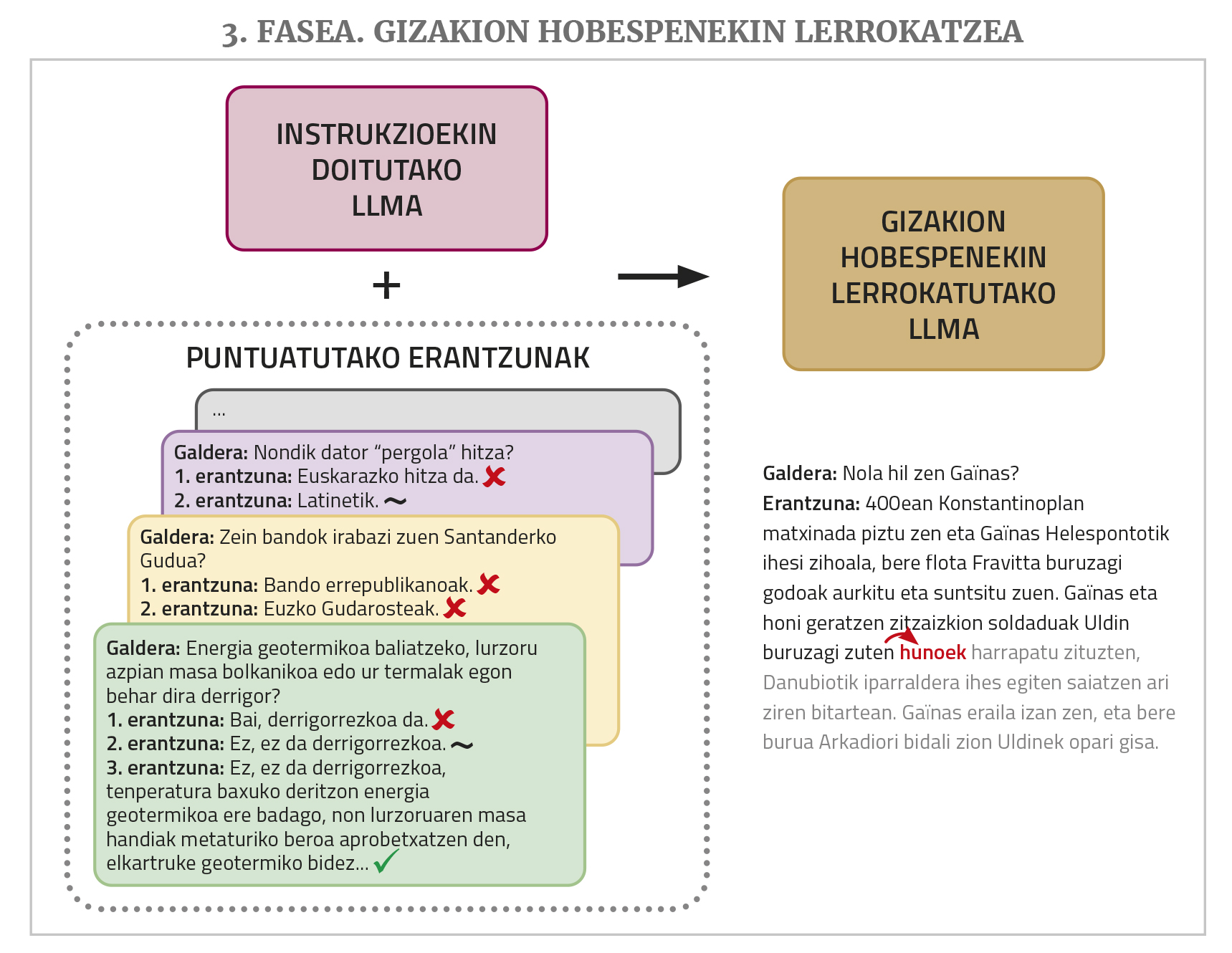
Finalmente, para un mejor funcionamiento se requiere una fase de entrenamiento denominada alineación con preferencias de seres humanos (alignment with human preferences, en inglés). Se pide a la MPR que realice varias tareas solicitando para cada una de ellas más de una posible respuesta y después varias personas evalúan esas respuestas. Estas respuestas puntuadas se utilizan en este último entrenamiento, lo que permite que las respuestas de los chatbots se ajusten mejor (“alinear”, utilizando el término del área) a las deseos o a la lógica de los seres humanos. Para realizar este paso existen diferentes técnicas como el aprendizaje de refuerzo mediante realimentación humana (en inglés, Reinforcement Learning from Human Feedback o RLHF) o la optimización de las prioridades directas (en inglés, Direct Preference Optimization o DPO).
Construcción de LLM propios en euskera
Más arriba hemos comentado que los LLM o los chatbots son multilingües, ya que generalmente se entrenan con textos de diferentes idiomas. Pero no funcionan igual para todos los idiomas, ya que el número de textos que se ven en el entrenamiento no es el mismo: la mayoría de los textos son en inglés, los de otros idiomas (incluso los de otros idiomas principales) son mucho menos, y no digamos los de los idiomas pequeños. Sin embargo, a pesar de estas diferencias, un LLM puede llegar a aprender todos los idiomas bastante bien debido a la propiedad de aprendizaje por transferencia (transfer learning, en inglés). Se ha demostrado que las redes neuronales ya tienen esa propiedad y, de alguna manera, aprovechan los conocimientos adquiridos en un dominio o en una o varias lenguas para poder aprender otro dominio o idioma con menos datos; en el caso de las lenguas, además, se necesitan menos datos si ya domina una lengua de la misma familia (en cierta medida ocurre de manera similar con los seres humanos). Así, aunque en el artículo anterior afirmábamos que el ChatGPT hablaba en euskera bastante bien, pero que todavía tenía mucho que mejorar, al pasar de GPT 3.5 a GPT 4, ha habido una mejora notable, y hay que reconocer que lo hace muy bien en euskera.
Aunque esto sea así, por varias razones (soberanía tecnológica, que el futuro de nuestra lengua no esté en manos de las multinacionales norteamericanas, pérdida de privacidad que supone el uso de las herramientas de los gigantes tecnológicos...), es conveniente desarrollar el LLM o los chatbots en euskera, y en eso estamos trabajando varias organizaciones del País Vasco.
Construir un LLM en euskera desde cero, sin embargo, no es tarea fácil. Para que funcionen bien, hay que entrenar con millones de palabras, y en euskera no hay tantas. El número de textos que se puede conseguir con la traducción automática es suficiente, y con eso también hemos realizado pruebas piloto, pero los resultados no han sido suficientes. Además, el entrenamiento completo de estas gigantescas redes requiere máquinas muy potentes y tarda muchísimo. Por ello, es muy caro y, por tanto, inviable.
Por ello, la vía que habitualmente se utiliza es la de adoptar un LLM fundacional libre, previamente entrenado, y realizar un ajuste fino o un fine-tuning para que pueda aprender mejor euskera. En definitiva, este ajuste supone continuar con el entrenamiento a través de textos en euskera, por lo que también se le denomina pre-entrenamiento continuado o continual pre-training. Se trata de que el LLM que se ha pre-entrenado ya sabe que tiene otros idiomas, que tiene un conocimiento general y otras competencias, y que gracias al aprendizaje por transferencia no necesita tanto tiempo de texto o entrenamiento para aprender euskera. Además, si se desea, se pueden utilizar técnicas como LoRA (Low-Rank Adaptation) para sustituir toda la red por una parte, reduciendo considerablemente las exigencias de memoria.
En los últimos trabajos en este camino se utiliza LLaMa desarrollado por la empresa Meta y que ha sido cedida en licencia libre. El centro HiTZ de la UPV/EHU, por ejemplo, tomando como base LLaMa 2 y siguiendo un entrenamiento con la colección de textos EusCrawl, sacó en enero del año pasado el LCM en euskera Latxa, que posteriormente, en abril, adaptó y mejoró con un corpus de texto mayor. Latxa obtuvo mejores resultados que cualquier otro LLM en las pruebas de competencia en euskera (evaluado con pruebas preliminares de EGA) y en las preguntas o tareas generales sólo superaba a GPT 4 (con conjuntos de evaluación preparados para preguntas generales, de comprensión lectora y de preguntas de oposiciones).
En nuestro centro de Tecnologías Orai NLP de Elhuyar, cogimos la LLLaMa 3.1 y la ajustamos con el corpus Zelai (Handi Orai Orai es la mayor colección de textos libres en euskera recopilados por Zelai Orai, con 521 millones de palabras), y el resultado es el de libre -eus-8B, presentado en septiembre del año pasado. Ha obtenido los mejores resultados en todos los tipos de tareas entre los modelos fundacionales en euskera ligeros (menos de 10 mil millones de parámetros), e incluso ofrece mejores resultados en algunas tareas que los modelos mucho más grandes.
¿Y los chatbots en euskera?
A la vista de estos resultados, uno puede pensar que ya tenemos una especie de ChatGPT en euskera que hemos creado aquí. Pero como hemos visto, los resultados que obtienen los modelos locales para muchos tipos de solicitudes de tareas en euskera todavía no alcanzan el nivel de GPT4, y sobre todo, los resultados son sensiblemente inferiores a los que se obtienen con el inglés.
La razón de ello la hemos explicado arriba: La obtención de un chatbot funcional desde un LLM requiere también un ajuste fino de instrucciones y fases de entrenamiento para alinearlo con las preferencias humanas. Se ha observado que una de las principales causas del buen rendimiento de los chatbot comerciales son las series de datos utilizadas en estos dos pasos, muy grandes y de calidad. Y este tipo de datos (conjuntos de soluciones de pedido y cuestionarios de respuesta evaluados por las personas), a diferencia de los textos que se pueden obtener de la red de pre-entrenamiento en cantidades relativamente elevadas de forma automática, exigen ser generados manualmente por las personas, lo que resulta muy costoso. Los gigantes tecnológicos le asignan mucho dinero y mano de obra, y esos paquetes de datos no los dejan sueltos. No hay recursos suficientes para crear este tipo de cosas en euskera. Existen algunos conjuntos de datos libres de este tipo, pero no son lo suficientemente grandes, no están en euskera, ... Incluso sin un ajuste de instrucciones fino se puede conseguir que ciertas tareas se hagan mejor con uno o varios ejemplos de la tarea que se quiere realizar en la propia pregunta (esta técnica se denomina prompt engineering o in-context learning), pero los resultados no son iguales a los que se obtienen con el ajuste.
Por todo ello, todavía queda mucho trabajo por hacer para tener nuestro propio chatbot funcional. Eso no quiere decir que no lo hagamos. En el centro Orai, por ejemplo, tenemos varios trabajos en marcha. Por ejemplo, más allá del conocimiento del euskera y de la respuesta a las demandas generales en euskera, hemos analizado si los LLM y los chatbots tienen conocimiento de Euskal Herria y de la cultura vasca, creando y facilitando una serie de datos para evaluarlo. El conjunto de datos está en inglés (al fin y al cabo, los chats de grandes empresas funcionan mejor en inglés y se quería evaluar el conocimiento de sus temas vascos, no la competencia en euskera) y se han hecho preguntas en inglés a los chatbot. La conclusión es que tienen un fuerte sesgo cultural y solo se aciertan de media alrededor del 20% de las preguntas de los temas vascos. Probando diferentes técnicas en modelos fundacionales libres, hemos intentado mejorarlo y las sesiones han sido exitosas, con una tasa de acierto que ha aumentado en torno al 80%. El centro HiTZ también ha realizado un trabajo similar y una evaluación.
En el centro Orai también trabajamos el sesgo de los LLM en euskera. Hemos traducido al euskera y adaptado al contexto vasco el conjunto de datos BBQ que se utiliza para medir los sesgos de la LLM, y lo hemos hecho público con la licencia libre BasqBBQ. Se han medido los sesgos de los LLM en euskera (Latxa y LLaMa-eus-8b) y se han comparado con los del modelo LLaMa original que los sustentan. Y se ha visto que los modelos adaptados al euskera no tienen mayor sesgo, sino todo lo contrario.

Por último, también hemos realizado los primeros experimentos sobre el refinado ajuste de las instrucciones y su alineación con las preferencias humanas. Para ello se han obtenido una serie de conjuntos de datos en inglés libremente disponibles, tanto de instrucciones (tipo de soluciones de pedido) como de respuestas puntuadas, y una vez traducidas al euskera mediante traducción automática, se han procedido a pasar estas otras dos fases de entrenamiento a nuestro modelo fundacional LLLaMa-eus-8B. Así, hemos construido el primer chatbot en euskera que ha pasado por todas las fases de entrenamiento. Y hemos comparado los resultados con el modelo de chat LLaMa de tamaño similar que Meta sacó con sus datos privados, ajustado a las instrucciones y alineado con las preferencias humanas, y hemos visto que el nuestro funciona mucho mejor en esas tareas creativas en euskera. Sin embargo, la calidad de los resultados aún no llega al modelo más cerrado como ChatGPT. Al fin y al cabo, como ya se ha dicho, los conjuntos de datos abiertos de instrucción y entrenamiento de DPO no son tan grandes como los de los gigantes tecnológicos, y además, el hecho de que hayan sido traducidos por traducción automática también tiene cierta influencia.
Todos estos trabajos, y muchos más, deberán ser realizados todavía para que se convierta en uno de los chatbot funcionales más utilizados en euskera. Pero, incluso cuando se consigue, puede ser un problema ponerlo a disposición de la sociedad vasca. De hecho, entrenar a estas gigantescas redes neuronales es tan caro como hacerlo, tener en marcha para poder utilizarlas también es muy caro, ya que necesitan máquinas muy potentes. Los gigantes tecnológicos estadounidenses que ofrecen los chats comerciales más exitosos están perdiendo una enorme cantidad de dinero por estar en la vanguardia de esta revolución y por ganar cuota de mercado. Estos modelos no son rentables y, por otra parte, el impacto ambiental de este tipo de máquinas grandes también está ahí. Por ello, la optimización es tan importante como mejorar los resultados de todos estos bots, es decir, obtener los mismos resultados utilizando redes neuronales más sostenibles económica y ecológicamente.
Y precisamente por ese camino va la LLM de código abierto de la empresa china DeepSeek, conocida a finales de enero como DeepSeek-V3. Las descargas de la APP para su uso superaron las de ChatGPT en Estados Unidos, ya que ofrecía resultados comparables con las suyas a un precio mucho más barato. Esto provocó un terremoto en las cotizaciones bursátiles de las empresas estadounidenses AA y chip y en las expectativas y expectativas de futuro. Pero además de la gran calidad de los resultados, el hecho es que, obligados por el embargo de los chips que China ha puesto a disposición de Estados Unidos, las LLM han tenido que buscar vías para poder desarrollarse en chips menos potentes.
Aprovechando algunas variantes que hasta ahora no han sido utilizadas por los demás en la estructura y entrenamiento de la LLM, la empresa afirma que el coste del entrenamiento de DeepSeek-V3 ha sido del 6% del GPT-4 y que solo ha requerido el 10% de la energía del entrenamiento de LLLaMa 3.1. El coste de ofrecer el modelo como servicio es mucho menor, por lo que se dice que es el único que no pierde dinero, aunque se ofrece más barato. Es decir, los resultados de DeepSeek son similares a los modelos más cerrados como ChatGPT, mejores que los de código abierto como LLaMa, es de código abierto y tiene menos de la décima parte de la necesidad energética (y por lo tanto de coste) de los otros modelos. Pronto se verá si se confirma la idoneidad de este camino, si los desarrolladores de otros modelos también lo toman, y también nos sirve para desarrollar y ofrecer modelos propios en euskera de una manera más rápida y económica.
