

La langue basque à travers les grands modèles linguistiques et les chatbots
2025/03/01 Leturia Azkarate, Igor - Informatikaria eta ikertzailea Iturria: Elhuyar aldizkaria
Depuis deux ans, des chatbots capables de répondre à toutes les questions et de faire toutes sortes de tâches sont apparus, et depuis lors ChatGPT, Gemini, Copilot, Claude et autres sont partout et largement utilisés. Ces outils sont basés sur de grands modèles linguistiques ou LLM (Large Language Models). Dans cet article, nous allons expliquer le chemin que l’euskara fait dans ces modèles. Et nous expliquerons également le fonctionnement des chatbots et des LLM, d’une part parce que nous pouvons comprendre les difficultés qu’il y a à faire progresser le basque, mais aussi parce qu’il est important de comprendre le fonctionnement de toute technologie omniprésente et de plus en plus nécessaire dans de nombreux domaines.

Il y a presque deux ans, nous avons écrit un article intitulé Le boom de l'intelligence artificielle créative dans ce coin. Et nous ne pouvons pas dire que depuis lors l'impact de cette explosion s'est atténué; au contraire, l'onde d'expansion de ce boom s'est répandue sans cesse et partout. Les systèmes d'intelligence artificielle ou d'IA créatrice mentionnés à l'époque étaient capables de créer du texte ou de l'image, car nous avons vu depuis des systèmes qui produisent de la musique (comme Suno), ainsi que de la vidéo (comme Sora d'OpenAI). Beaucoup de nouveaux chatbots sont apparus: Copilot de Microsoft, Claude d'Anthropic, Gemini de Google, Meta Meta AI, Perplexity, Jasper AI... Et il y a aussi une augmentation du LLM (Large Language Model) ou de nouveaux grands modèles linguistiques ou de nouvelles versions des anciens: PaLM, GPT-4, Grok, Gemini, Claude... Le paysage a également beaucoup changé dans les LLM en licence libre avec l'apparition d'OpenAssistant, Mixtral, Gemma, Qwen et surtout LLaMa de Meta-.
LLM ou Grand Modèle Linguistique
Il n'est pas facile de suivre le fil de cette soupe de noms et de concepts. Mais au moins il est pratique et intéressant de savoir ce qu'est un LLM, qu'est-ce qu'un chatbot, et comment ils se développent.
On peut dire que depuis deux ou trois ans nous vivons une nouvelle ère dans les technologies linguistiques et vocales, l'ère des grands modèles linguistiques ou des LLM. Les LLM sont une sorte de réseau neuronal profond, capable, d’une part, de bien répondre à de nombreux problèmes non résolus jusqu’à présent (création automatique de textes, réponse à des questions de tout type, écriture de logiciels...) et, d’autre part, de réaliser aussi bien ou mieux qu’eux de nombreuses tâches déjà effectuées avec d’autres types de réseau neuronal profond (traduction automatique, résumé automatique...). Après tout, tout travail textuel peut être fait par LLM aujourd'hui (et dans de nombreux cas, il est fait).
Les LLM sont des réseaux neuronaux profonds, transformables, dans lesquels la plupart appartiennent à la classe des simples décodeurs. Mais au-delà de la structure, ils ont plusieurs autres caractéristiques importantes. D'une part, il s'agit de réseaux gigantesques: ils ont de nombreux nœuds d'entrée et de nombreuses couches intermédiaires chacune avec de nombreux nœuds; les liens entre ces nœuds ou les paramètres que le réseau doit apprendre sont généralement des milliards. D'autre part, ils s'entraînent avec des textes vides, mais avec un nombre impressionnant de textes, avec des collections de textes allant jusqu'à des millions de mots. Enfin, ils sont généralement multilingues, c'est-à-dire qu'ils s'entraînent avec des textes dans de nombreuses langues et fonctionnent dans toutes ces langues (mais mieux parfois que dans d'autres, comme vous le verrez plus tard).
La mission de LLM est en principe une chose unique et très simple: en donnant une succession de mots, en tenant compte des séquences de mots que vous avez vues pendant l'entraînement, prédire le prochain mot le plus probable. C’est-à-dire, si nous donnons à l’entrée une séquence de “noix éloignées quatorze,” il devrait retourner “approcher”. Et c'est tout ce qu'un LLM fait. Le fait est que si nous lui donnons ensuite « Noix distantes quatorze, approchez », il traduira « et », si nous le refaisons « quatre »... Et ainsi, à travers ce processus dit d’auto-régression, nous pouvons mettre en place de longs textes ou réponses. En outre, comme nous l’avons déjà dit, ils peuvent contenir de nombreux nœuds à l’entrée, voire des milliers, ce qui permet que les textes ou les demandes entrants (les « prompt », en utilisant le terme de domaine) soient très longs et complexes.
En réalité, les LLM ne fonctionnent pas avec des mots, mais avec des chiffres. Et comme il faut trop de nombres pour exprimer tous les mots dans de nombreuses langues, ils travaillent avec des fragments de mots appelés «token». Mais pour faciliter les explications, nous dirons qu'ils prennent les mots.
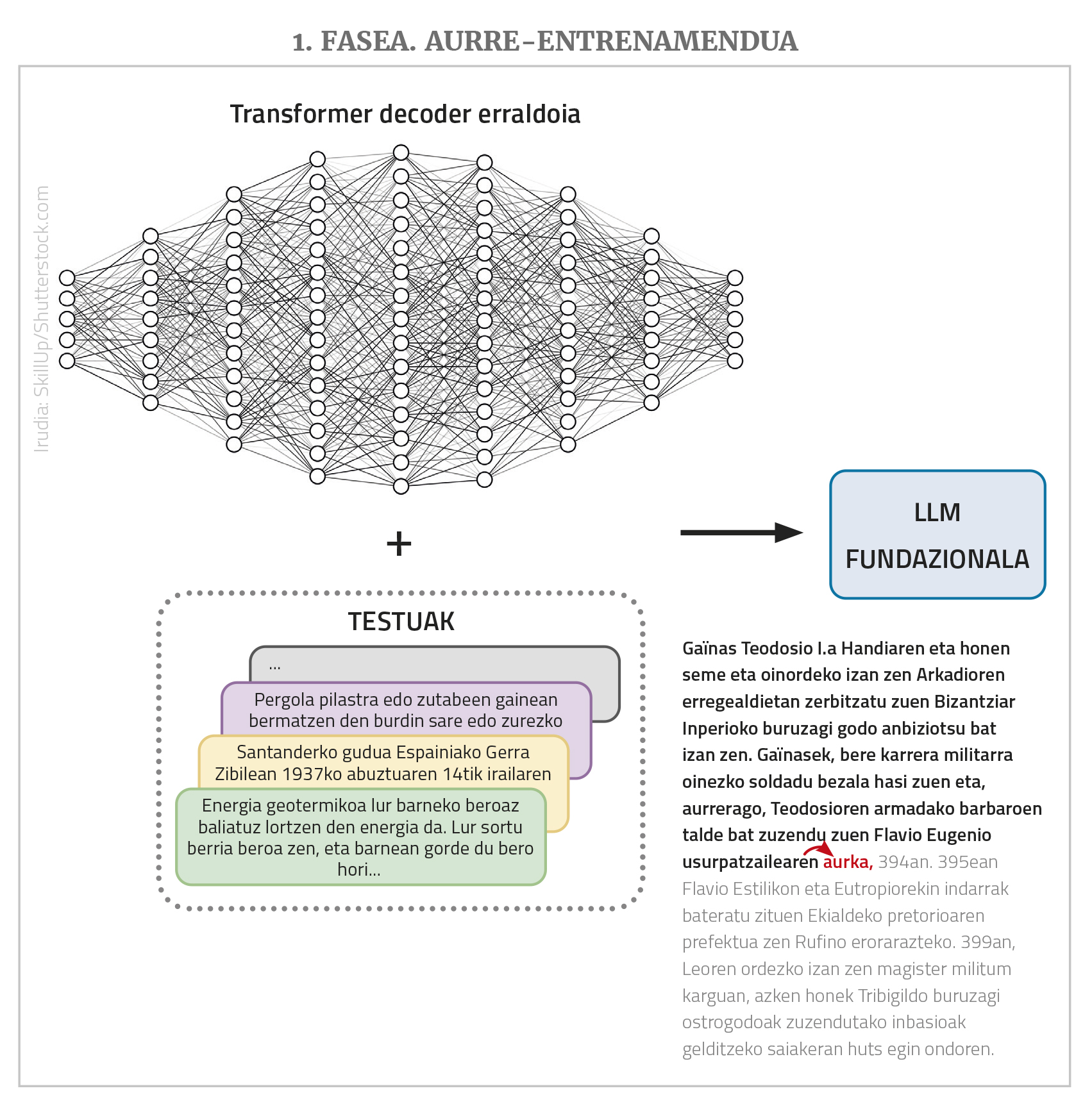
En résumé, il s'agit donc d'un LLM: un gigantesque réseau neuronal de type transformateur (généralement de la classe decoder) qui prévoit le mot suivant en fournissant un texte long et qui a été pré-formé à cet effet avec de nombreux textes en plusieurs langues (nous verrons plus loin pourquoi «avant» - formation). Les LLM dans cet état de base reçoivent également plusieurs autres noms: modèle de base, GPT (Generative Pre-Trained Transformer), modèle de langage auto-régressif... En raison des grandes dimensions du réseau et de la collection d'entraînement, les textes qu'il produit sont généralement corrects sur le plan linguistique, appropriés au niveau de la morphologie, de la syntaxe et de la sémantique, et démontrent en général une grande connaissance du monde et d'autres compétences.
Des LLM aux chatbots
Un chatbot comme ChatGPT ou Gemini a un tel LLM à la base, mais il a encore besoin de deux étapes d'entraînement supplémentaires: un réglage fin des instructions et l'alignement avec les préférences humaines.
Un LLM, comme mentionné ci-dessus, suit un texte qui lui est donné dans l'introduction. Mais les chatbots reçoivent des questions ou des demandes pour effectuer une tâche. Face à cela, il est possible que le LLM réponde bien s’il a vu des réponses à des questions ou des solutions de demande similaires dans les textes de formation. Mais il n'y en a pas beaucoup dans les corpus d'entraînement. C'est la raison pour laquelle, pour mieux remplir son rôle de chatbot, le LLM a besoin d'une autre phase d'entraînement appelée «réglage fin de l'instruction». Pour cette formation, il est nécessaire de compléter une collection d'instructions pour les différents types de tâches pour lesquelles des chatbots sont souhaités, à savoir des exemples de solutions de demande par paires: questions avec réponses, demandes de résumé avec résumés, demandes de correction de textes incorrects avec corrections correspondantes, demandes de traduction avec traductions, demandes de création de textes avec textes... Le LLM apprend ainsi à apporter une réponse appropriée à ces types de demandes.
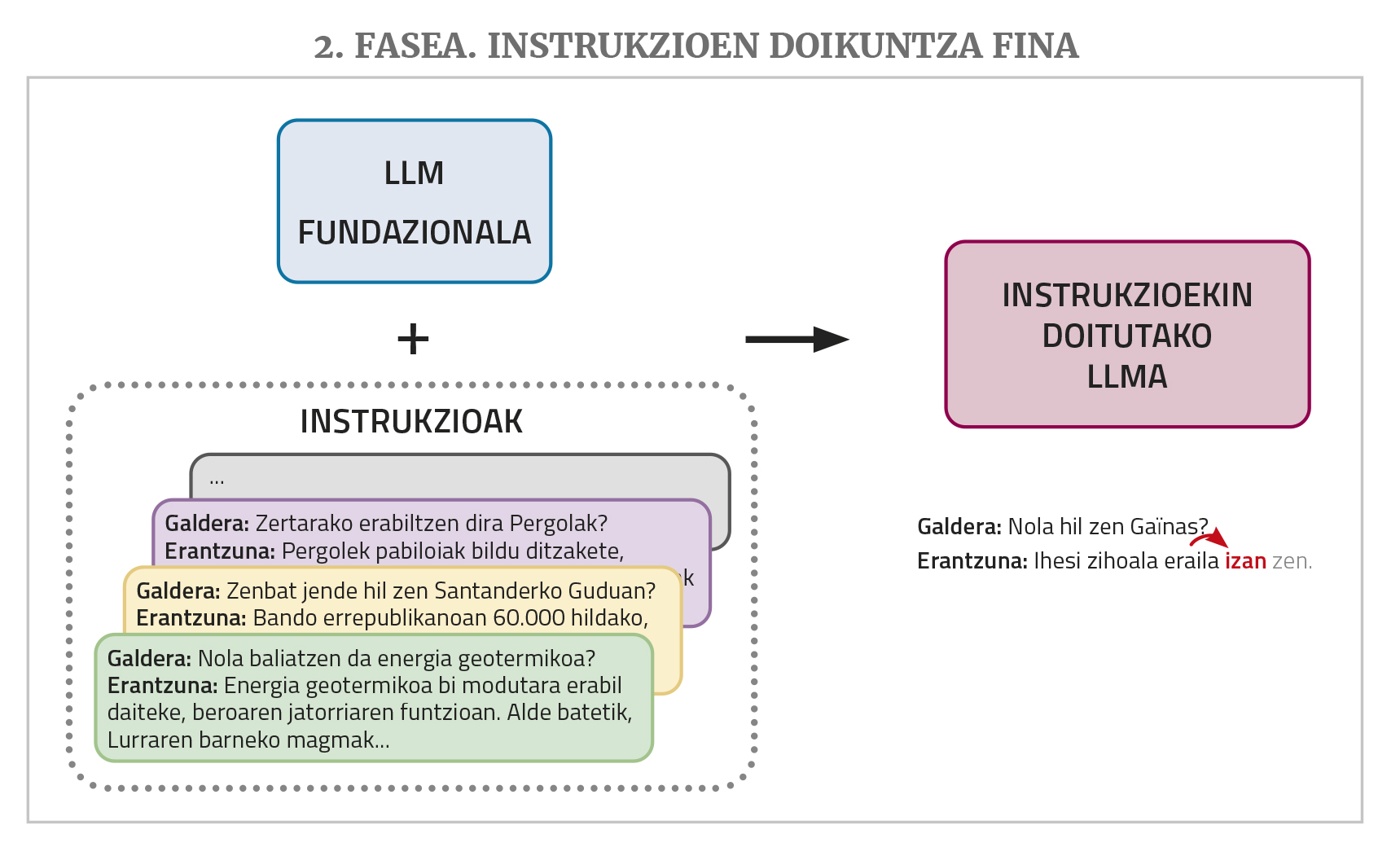
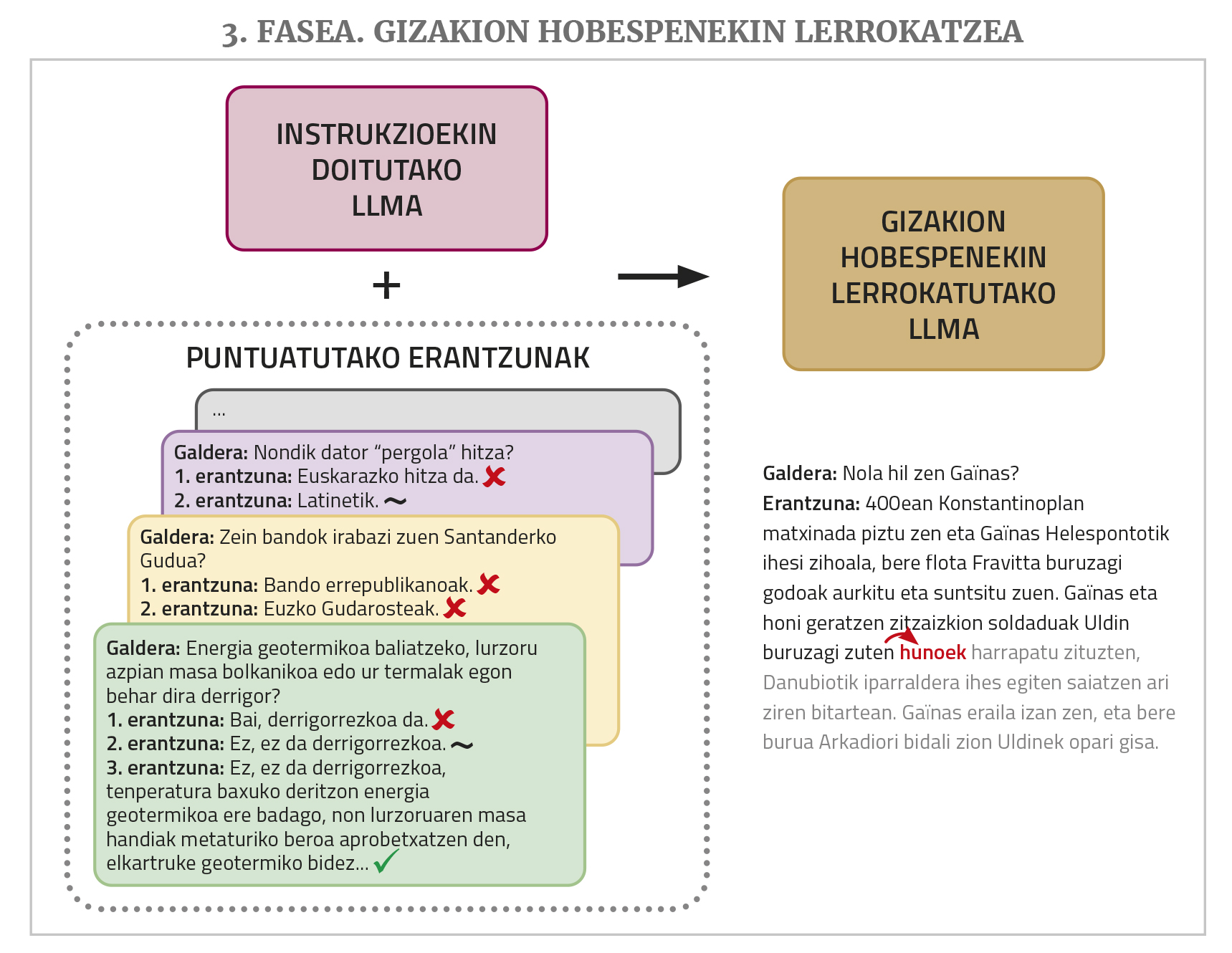
Pour terminer, pour que cela fonctionne mieux, une phase d'entraînement appelée alignment with human preferences (alignment with human preferences) est nécessaire. Le LLM est invité à effectuer plusieurs tâches, en demandant plusieurs réponses possibles pour chacune, puis plusieurs personnes évaluent ces réponses. Ces réponses ponctuées sont utilisées lors de cette dernière formation, ce qui permet de mieux aligner les réponses des chatbots (« alignement », en utilisant le terme de domaine) avec les désirs ou la logique humaine. Pour ce faire, il existe différentes techniques, telles que l’apprentissage du renforcement par réalimentation humaine (RLHF) ou l’optimisation des préférences directes (DPO).
Construisez vos propres LLM en basque
Nous avons dit plus haut que les LLM ou les chatbots sont multilingues, car ils sont généralement entraînés avec des textes de différentes langues. Mais ils ne fonctionnent pas de la même manière pour toutes les langues, car le nombre de textes observés pendant l'entraînement n'est pas le même: la grande majorité des textes sont en anglais, ceux des autres langues (y compris les autres langues principales) sont beaucoup moins nombreux et certainement pas des petites langues. Cependant, malgré ces différences, un LLM peut arriver à apprendre assez bien toutes les langues en raison de la propriété appelée apprentissage par transfert (transfer learning). Il a été démontré que les réseaux neuronaux possèdent cette propriété qui leur permet de tirer parti des connaissances acquises d'une manière ou d'une autre dans un ou plusieurs domaines ou langues pour apprendre un autre domaine ou une autre langue avec moins de données; dans le cas des langues, en outre, moins de données seront nécessaires si vous maîtrisez déjà une langue de la même famille (il en est de même pour les humains dans une certaine mesure). Ainsi, bien que nous disions dans cet article que ChatGPT faisait assez bien en basque mais qu'il avait encore beaucoup à améliorer, en passant de GPT 3,5 à GPT 4, il a connu une amélioration significative et il faut reconnaître qu'il le fait très bien en basque.
Malgré cela, pour diverses raisons (souveraineté technologique, le fait que l’avenir de notre langue ne soit pas entre les mains des multinationales américaines, la perte de la vie privée liée à l’utilisation d’outils de géants technologiques...), il convient de développer localement le LLM ou les chatbots en basque, et c’est ce que font certaines institutions du Pays Basque.
Construire un LLM basque à partir de zéro, cependant, n'est pas une tâche facile. Pour bien fonctionner, il faut s'entraîner avec des millions de mots et il n'y en a pas beaucoup en basque. Il est possible d'obtenir un nombre suffisant de textes en utilisant la traduction automatique, avec laquelle nous avons également effectué des tests pilotes, mais les résultats n'ont pas été assez bons. En outre, l'entraînement complet de ces réseaux géants nécessite des machines très puissantes et prend énormément de temps. De ce fait, il est très coûteux et donc non viable.
C'est la raison pour laquelle il est courant d'adopter un LLM libre et pré-formé et d'y effectuer un réglage fin ou fine-tuning afin qu'il apprenne mieux le basque. Après tout, cet ajustement consiste à poursuivre l'entraînement à l'aide de textes basques, c'est pourquoi on l'appelle aussi pré-entraînement continu ou pré-entraînement continu. Le fait est que ce LLM préformé sait déjà qu'il a d'autres langues, des connaissances générales et d'autres compétences et que, grâce à l'apprentissage par transfert, l'apprentissage du basque ne nécessite pas autant de textes ou de temps de formation. En outre, des techniques telles que LoRA (Low-Rank Adaptation) peuvent être utilisées si l'on veut remplacer l'ensemble du réseau par un simple ajustement partiel, ce qui réduit considérablement les besoins en mémoire.
Les travaux récents sur cette voie utilisent le LLaMa développé par Meta et mis en licence libre. Le Centre HiTZ de l'EHU, par exemple, en s'appuyant sur la base LLaMa 2 et en poursuivant sa formation avec la collection de textes EusCrawl, a lancé le LLM basque Latxa en janvier de l'année dernière, qu'il a ensuite adapté et amélioré en avril avec un plus grand corpus de textes. Latxa a obtenu de meilleurs résultats que n'importe quel autre LLM dans le test de compétence en euskara (évalué avec les tests préliminaires de l'EGA), et dans les questions ou les tâches générales, elle dépassait seulement GPT 4 (avec quelques ensembles d'évaluation qu'ils avaient préparés pour les questions générales, les questions de compréhension de lecture et les questions d'opposition).
Dans notre centre Orai NLP Technologies d’Elhuyar, nous avons pris LLaMa 3.1 et l’avons ajusté avec le corpus Far (c’est la plus grande collection de textes libres en basque collectée par Far Orai de 521 millions de mots), et le résultat est Llama-eus-8B, qui a été présenté en septembre de l’année dernière. Il a obtenu les meilleurs résultats parmi les modèles basques légers (moins de 10 milliards de paramètres) dans tous les types de tâches et donne même de meilleurs résultats dans certaines tâches que les modèles beaucoup plus grands.
Et les chatbots en basque ?
Au vu de ces résultats, on peut penser que nous avons déjà une sorte de ChatGPT en basque créé localement. Mais comme nous l'avons vu, les résultats obtenus par les modèles locaux pour de nombreux types de demandes de tâches en basque ne sont pas encore au niveau de GPT4, et surtout, les résultats sont nettement inférieurs à ceux obtenus avec l'anglais.
Nous en avons expliqué la raison ci-dessus: Pour obtenir un chatbot fonctionnel à partir d'un LLM, il est également nécessaire d'ajuster minutieusement les instructions et les phases d'entraînement pour s'aligner avec les préférences humaines. Il a été constaté que l'une des principales raisons de la bonne performance des chatbots commerciaux réside dans les ensembles de données très volumineux et de qualité utilisés dans ces deux étapes. Et ces types de données (ensembles de solutions de demande et de réponses évaluées par des personnes), contrairement aux textes qui peuvent être obtenus en grande quantité de manière assez automatique à partir du réseau de pré-formation, doivent être générés manuellement par des personnes, ce qui est très coûteux. Les géants de la technologie y consacrent beaucoup d'argent et de main-d'œuvre, et ces lots de données ne les libèrent pas. Il n'y a pas assez de ressources pour les créer. S'il existe des ensembles de données libres de ce type, mais qui ne sont pas assez volumineux, ils ne sont pas en basque... Même sans un ajustement minutieux des instructions, il est possible d’obtenir une meilleure exécution de certaines tâches en donnant un ou plusieurs exemples de la tâche que vous voulez effectuer dans la question elle-même (cette technique est appelée prompt engineering ou in-context learning), mais les résultats ne sont pas aussi bons que ceux obtenus avec l’ajustement.
Pour toutes ces raisons, il y a encore beaucoup de travail à faire pour avoir notre propre chatbot fonctionnel. Ça ne veut pas dire qu'on ne fait pas ça. Au centre d'Orai, par exemple, nous avons des travaux en cours. Par exemple, au-delà de la connaissance du basque et de la réponse aux demandes générales en basque, nous avons étudié si le LLM et les chatbots ont une connaissance du Pays Basque et de la culture basque, en créant et en mettant à disposition une série de données pour l’évaluer. La série de données est en anglais (après tout, les chatbots des grandes entreprises fonctionnent mieux en anglais et il s'agissait d'évaluer leurs connaissances sur les sujets basques plutôt que leur capacité en basque) et des questions ont été posées aux chatbots en anglais. La conclusion est qu'ils ont un fort biais culturel et ne réussissent qu'environ 20% des questions sur les sujets basques en moyenne. En testant différentes techniques dans des modèles libres de base, nous avons essayé de l'améliorer et les séances ont été couronnées de succès, avec un taux d'invention qui a augmenté jusqu'à environ 80%. Le Centre HiTZ a également réalisé un travail similaire et une évaluation.
Nous avons également un biais des LLM basques dans le centre langai Orai. Nous avons traduit et adapté la série de données BBQ utilisée pour mesurer les biais de LLM dans le contexte basque et les avons rendues publiques sous une licence libre appelée BasqBBQ. Cela a permis de mesurer les biais des LLM basques (Latxa et LLaMa-eus-8b) et de les comparer à ceux du modèle LLaMa d'origine qui les sous-tendent. Et on a vu que les modèles adaptés au basque n'ont pas plus de biais, mais au contraire.

Enfin, nous avons également réalisé les premières expériences sur l'ajustement fin des instructions et l'alignement avec les préférences humaines. Pour ce faire, nous avons acquis plusieurs séries de données en anglais librement disponibles, à la fois des instructions (type de solution de demande) et des réponses ponctuées, et, après la traduction automatique en basque, nous avons passé ces deux autres phases d'entraînement à notre modèle fondateur LLaMa-eus-8B. Ce faisant, nous avons construit le premier chat basque qui a passé par toutes les phases d'entraînement. Et nous avons comparé les résultats avec ceux du modèle de chat LLaMa de taille similaire extrait par Meta, en utilisant ses données privées, ajusté avec les instructions et aligné avec les préférences humaines, et nous avons vu que le nôtre fonctionne beaucoup mieux dans ces tâches de création en basque. Cependant, la qualité des résultats n'atteint pas encore ce que ces modèles obtiennent dans les tâches en anglais, et moins dans le modèle plus fermé comme ChatGPT. Après tout, comme on l'a déjà dit, les ensembles de données ouvertes pour l'instruction et la DPOformation ne sont pas aussi volumineux que ceux dont disposent les géants de la technologie et, en outre, leur traduction automatique a également un certain impact.
Tous ces travaux et bien d'autres doivent encore être réalisés pour être l'un de tous les chatbots basques fonctionnels. Mais même si l'on parvient à l'obtenir, le problème peut être de le rendre disponible de manière à ce que la société basque puisse l'utiliser. En fait, tout comme il est coûteux de former ces réseaux neuronaux géants, il est également très coûteux de les utiliser en fonctionnement, car ils ont besoin de machines très puissantes. Les géants de la technologie des États-Unis qui proposent les chatbots commerciaux les plus performants le font parce qu'ils sont à l'avant-garde de cette révolution et qu'ils gagnent des parts de marché, mais ils perdent une énorme somme d'argent. Ces modèles ne sont pas rentables et, d'autre part, il y a aussi les dommages causés à l'environnement par de telles grandes machines. C'est pourquoi l'optimisation est aussi importante que l'amélioration des résultats de tous ces chatbots, c'est-à-dire obtenir les mêmes résultats en utilisant des réseaux neuronaux économiquement et écologiquement plus durables.
Et c'est exactement sur cette voie que se dirige le LLM open source de la société chinoise DeepSeek, DeepSeek-V3, qui est devenu populaire à la fin du mois de janvier. Les téléchargements de l'application pour l'utiliser ont dépassé ceux de ChatGPT aux États-Unis, offrant des résultats comparables à ceux de ChatGPT à un prix beaucoup plus bas. Cela a provoqué un tremblement de terre dans les cours boursiers des entreprises américaines AA et puces, ainsi que dans les intentions et les espoirs futurs. Mais au-delà de la haute qualité des résultats, le fait est que l’embargo américain sur les puces imposé à la Chine les a contraints à chercher des moyens de développer les LLM sur des puces moins puissantes, et apparemment ils l’ont inventé.
Profitant de plusieurs variantes de la structure et de l'entraînement du LLM que d'autres n'ont pas utilisées jusqu'à présent, la société affirme que le coût de l'entraînement du DeepSeek-V3 a été de 6% de celui du GPT-4 et a seulement besoin de 10% de l'énergie de l'entraînement du LLaMa 3.1. Le coût de la fourniture du modèle en tant que service est également beaucoup plus faible, de sorte que le seul qui ne perd pas de l'argent, même s'il est offert à un prix inférieur. En d'autres termes, les résultats de DeepSeek sont comparables aux modèles les plus fermés comme ChatGPT, meilleurs que les modèles open source comme LLaMa, qui est open source et prétend avoir moins du dixième du besoin énergétique (et donc du coût) des autres modèles. Nous verrons bientôt si la pertinence de cette voie est confirmée, si les développeurs des autres modèles empruntent également cette voie, et afin que nous puissions développer et offrir nos propres modèles basques, qui nous sont également utiles, plus rapidement et à moindre coût.
