

O eúscaro facendo camiño nos grandes modelos lingüísticos e nos chatbots
2025/03/01 Leturia Azkarate, Igor - Informatikaria eta ikertzailea Iturria: Elhuyar aldizkaria
Hai xa dous anos que apareceron chatbots capaces de responder a calquera pregunta e realizar todo tipo de tarefas, e desde entón ChatGPT, Gemini, Copilot, Claude e compañía están en todas partes e son moi utilizados. Estes instrumentos baséanse en grandes modelos lingüísticos e/ou LLM (Large Language Models). Neste artigo explicaremos o camiño que está a percorrer o eúscaro nestes modelos. Tamén explicaremos o funcionamento dos chatbots e das LLM, para que o eúscaro poida entender as dificultades que existen para avanzar neles, pero tamén porque é importante entender o funcionamento de calquera tecnoloxía omnipresente e cada vez máis necesaria en moitos campos.

Hai case dous anos escribimos neste espazo o artigo titulado O boom da intelixencia artificial creativa. E non podemos dicir que desde entón a explosión diminúa a súa influencia; pola contra, a onda expansiva do boom propagouse continuamente e en todas partes. Entón os sistemas de Intelixencia Artificial ou AA creativos eran capaces de crear texto ou imaxe; pois desde entón vimos sistemas que xeran música (como Suno) e tamén vídeo (como o Sora de OpenAI). Apareceron numerosos chatbot novos: Copilot de Microsoft, Claude de Anthropic, Gemini de Google, Meta AI, Perplexity, Jasper AI... Tamén se multiplicaron os LLM (Large Language Model) ou novos modelos lingüísticos ou versións dos anteriores: PaLM, GPT-4, Grok, Gemini, Claude... Así mesmo, o panorama cambiou moito nos LLM de licenza libre coa aparición de OpenAssistant, Mixtral, Gemma, Qwen e, sobre todo, LLaM de Meta.
LLM ou Gran Modelo Lingüístico
Non é fácil seguir o fío desta sopa de nomes e conceptos. Pero polo menos é conveniente e interesante saber que é un LLM, que é un chatbot e como se desenvolven.
Pódese dicir que desde fai dous ou tres anos estamos a vivir unha nova era nas tecnoloxías da lingua e da fala, a era dos grandes modelos lingüísticos ou dos LLM. Os LLM son un tipo de rede neuronal profunda capaz de responder correctamente a moitos problemas que até agora non foran resoltos (creación automática de textos, resposta a preguntas de calquera tipo, redacción de programas informáticos...) e de realizar moitas tarefas que xa se realizaban con outros tipos de redes neuronais profundas (tradución automática, resumo automático...). En definitiva, calquera traballo en texto pódese realizar na actualidade (e en moitos casos faise) a través de LLM.
Os LLM son redes neuronais profundas, tipo transformador, na súa maioría de clase de decoder simple. Pero máis aló da estrutura, teñen outras moitas características importantes. Por unha banda, trátase de redes xigantescas que teñen moitos nodos de entrada e moitas capas intermedias con moitos nodos; enlácelos ou parámetros que a rede debe aprender son miles de millóns. Doutra banda, adéstranse con textos buxán, pero cun gran número de textos, até millóns de palabras. Por último, adoitan ser plurilingües, é dicir, adéstranse con textos de diferentes idiomas e funcionan en todos eles (aínda que mellor nalgúns casos que noutros, como se verá máis tarde).
A misión de LLM é, en principio, unha cousa única e moi simple: dar unha secuencia de palabras e predicir a seguinte palabra máis probable a partir das secuencias de palabras que viu durante o adestramento. É dicir, si na entrada dámoslle a serie “catorce noces remotas”, el debería traducila “achegala”. E iso é o único que fai un LLM. O que pasa é que si lle damos a “achegarnos catorce noces remotas, e” devolverá “e”, si facémolo de novo “catro”… E así, a través deste proceso de auto-regresión podemos pór en produción textos ou respostas longas. Ademais, como se dixo, poden ter moitos nodos á entrada, incluso algúns miles, o que permite que os textos ou peticións de entrada (os “prompt”, utilizando o termo da área) sexan moi longos e complexos.
En realidade, os LLM non funcionan con palabras, senón con números. E como para expresar todas as palabras de moitos idiomas necesítanse demasiados números, traballan coas palabras que se chaman “token”. Pero para facilitar as explicacións, diremos que toman as palabras.
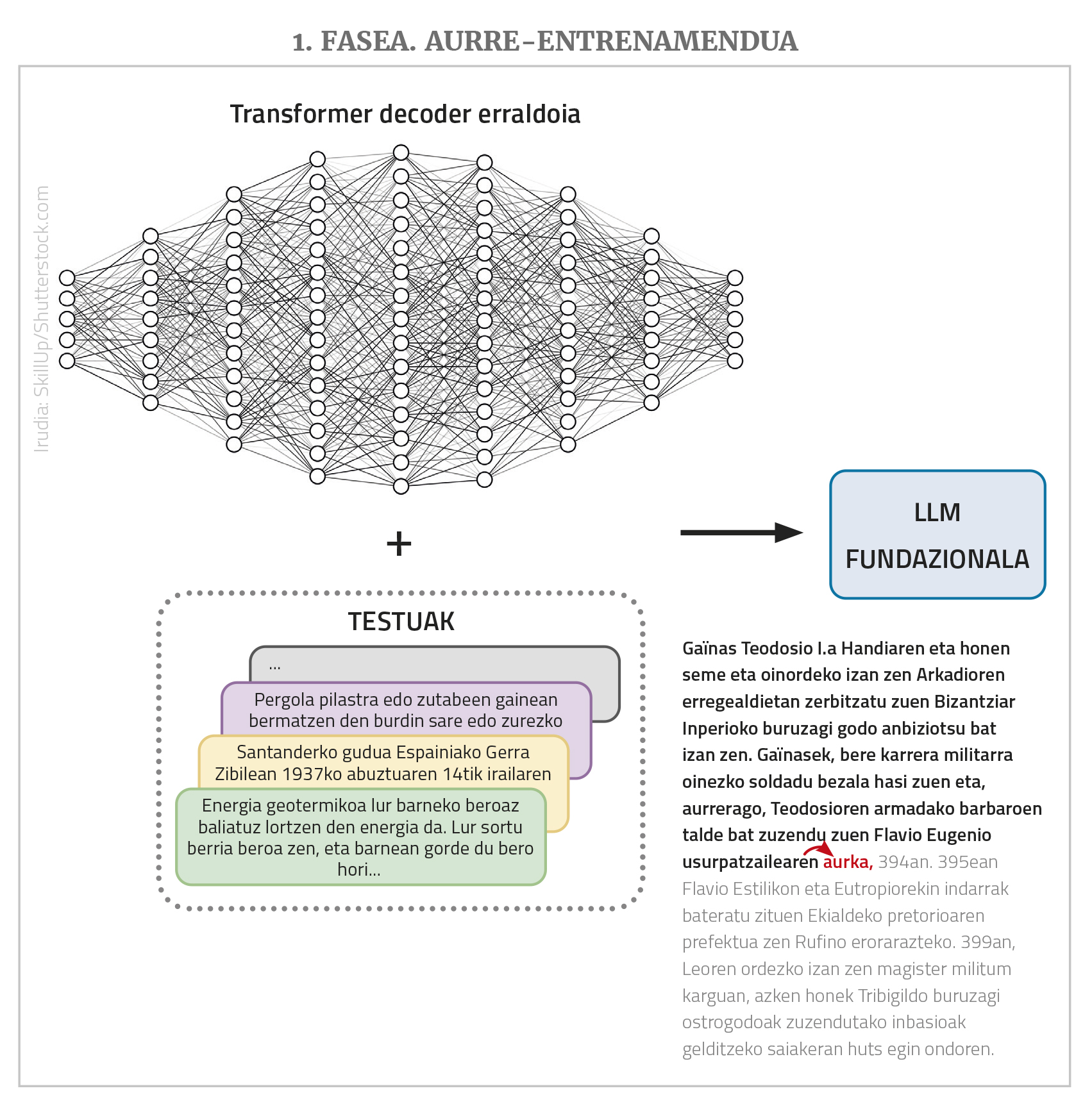
Por tanto, resumindo, un LLM é unha rede neuronal xigante tipo transformador (normalmente de clase decoder) que, cun texto extenso, prevé a seguinte palabra, e para iso adestrouse previamente con moitos textos de diferentes idiomas (máis adiante veremos por que “adiante”-----------). Os LLM que se atopan nesta situación básica tamén reciben outros nomes: modelo fundacional, GPT (Generative Pre-Trained Transformer), modelo lingüístico autoregresivo... Debido ás grandes dimensións da rede e da colección de adestramentos, os textos que xera son normalmente lingüisticamente correctos, adecuados aos niveis de morfología, sintaxes e semántica, mostrando un gran coñecemento do mundo e outras capacidades en xeral.
De LLM a chatbot
Un chatbot como ChatGPT ou Gemini baséase nun LLM deste tipo, pero aínda necesita dous pasos de adestramento: un axuste fino de instrucións e unha aliñación coas preferencias humanas.
Un LLM, como se mencionou anteriormente, dá continuidade a un texto que se lle dá na introdución. Pero aos chatbots dánselles preguntas ou peticións para facer unha tarefa. Ante este tipo de situacións, é posible que o LLM responda correctamente si nos textos de adestramento viu respostas de preguntas ou peticións similares. Pero nos corpus de adestramento non adoita haber moito. Por iso, para un mellor desempeño do traballo de chatbot o LLM necesita unha nova fase de adestramento denominada axuste fino de instrucións (instruction fine-tuning en inglés). Este adestramento consiste na elaboración dunha colección de instrucións para os diferentes tipos de tarefas que se desexan realizar, isto é, exemplos de pares de solucións de pedido: preguntas con respostas, solicitudes de resumos con resumos, solicitudes de corrección de textos incorrectos coas correccións oportunas, solicitudes de tradución con tradución, solicitudes de creación de textos con texto, etc. Desta maneira, a MPR aprende a dar unha resposta axeitada a este tipo de demandas.
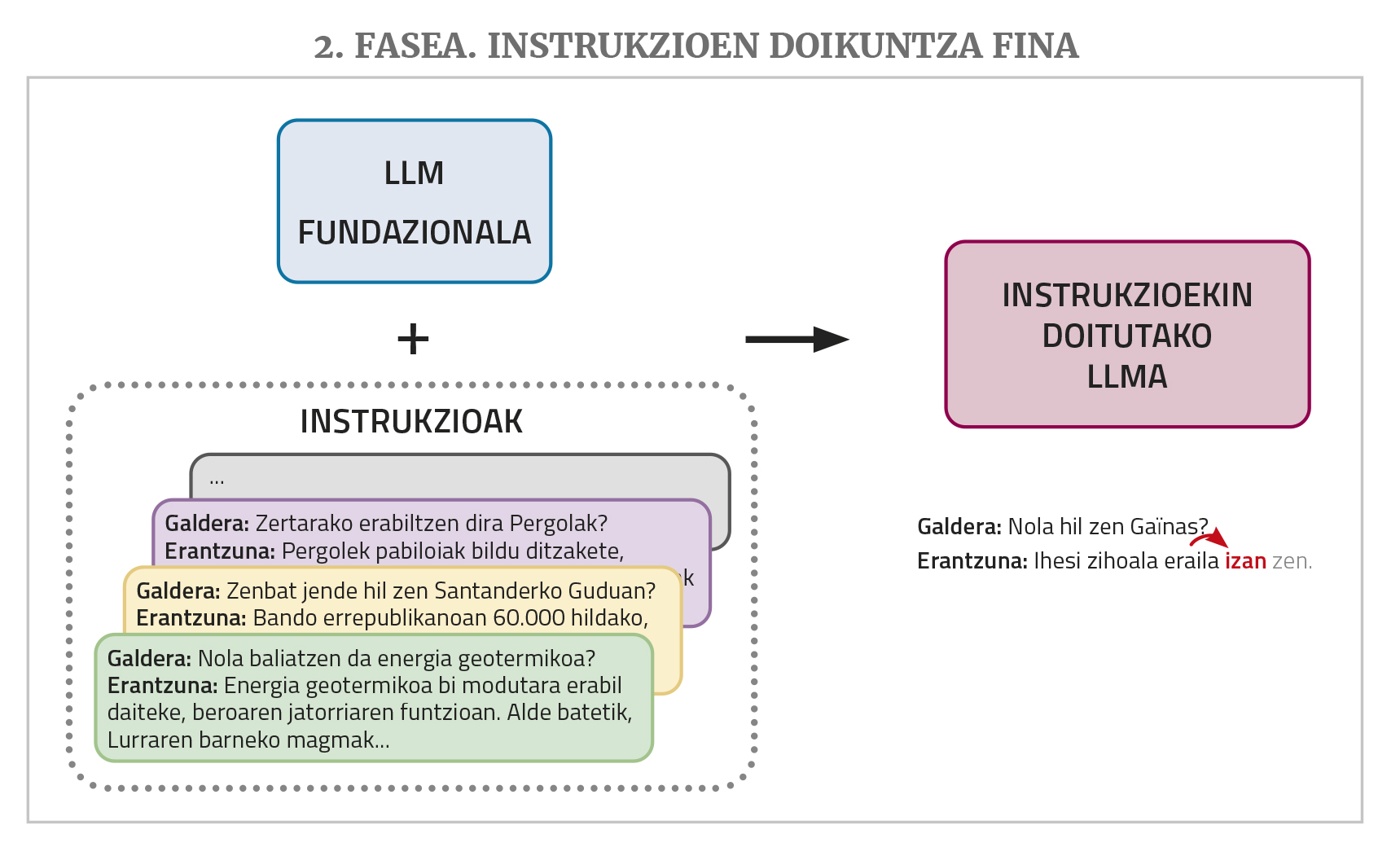
Finalmente, para un mellor funcionamento requírese unha fase de adestramento denominada aliñación con preferencias de seres humanos (alignment with human preferences, en inglés). Pídese á MPR que realice varias tarefas solicitando para cada unha delas máis dunha posible resposta e despois varias persoas avalían esas respostas. Estas respostas puntuadas utilízanse neste último adestramento, o que permite que as respostas dos chatbots axústense mellor (“aliñar”, utilizando o termo da área) aos desexos ou á lóxica dos seres humanos. Para realizar este paso existen diferentes técnicas como a aprendizaxe de reforzo mediante realimentación humana (en inglés, Reinforcement Learning from Human Feedback ou RLHF) ou a optimización das prioridades directas (en inglés, Direct Preference Optimization ou DPO).
Construción de LLM propios en eúscaro
Máis arriba comentamos que os LLM ou os chatbots son multilingües, xa que xeralmente se adestran con textos de diferentes idiomas. Pero non funcionan igual para todos os idiomas, xa que o número de textos que ven no adestramento non é o mesmo: a maioría dos textos son en inglés, os doutros idiomas (incluso os doutros idiomas principais) son moito menos, e non digamos os dos idiomas pequenos. Con todo, a pesar destas diferenzas, un LLM pode chegar a aprender todos os idiomas bastante ben debido á propiedade de aprendizaxe por transferencia (transfer learning, en inglés). Demostrouse que as redes neuronais xa teñen esa propiedade e, dalgunha maneira, aproveitan os coñecementos adquiridos nun dominio ou nunha ou varias linguas para poder aprender outro dominio ou idioma con menos datos; no caso das linguas, ademais, necesítanse menos datos se xa domina unha lingua da mesma familia (en certa medida ocorre de maneira similar cos seres humanos). Así, aínda que no artigo anterior afirmabamos que o ChatGPT falaba en eúscaro bastante ben, pero que aínda tiña moito que mellorar, ao pasar de GPT 3.5 a GPT 4, houbo unha mellora notable, e hai que recoñecer que o fai moi ben en eúscaro.
Aínda que isto sexa así, por varias razóns (soberanía tecnolóxica, que o futuro da nosa lingua non estea en mans das multinacionais norteamericanas, perda de privacidade que supón o uso das ferramentas dos xigantes tecnolóxicos...), é conveniente desenvolver o LLM ou os chatbots en eúscaro, e niso estamos a traballar varias organizacións do País Vasco.
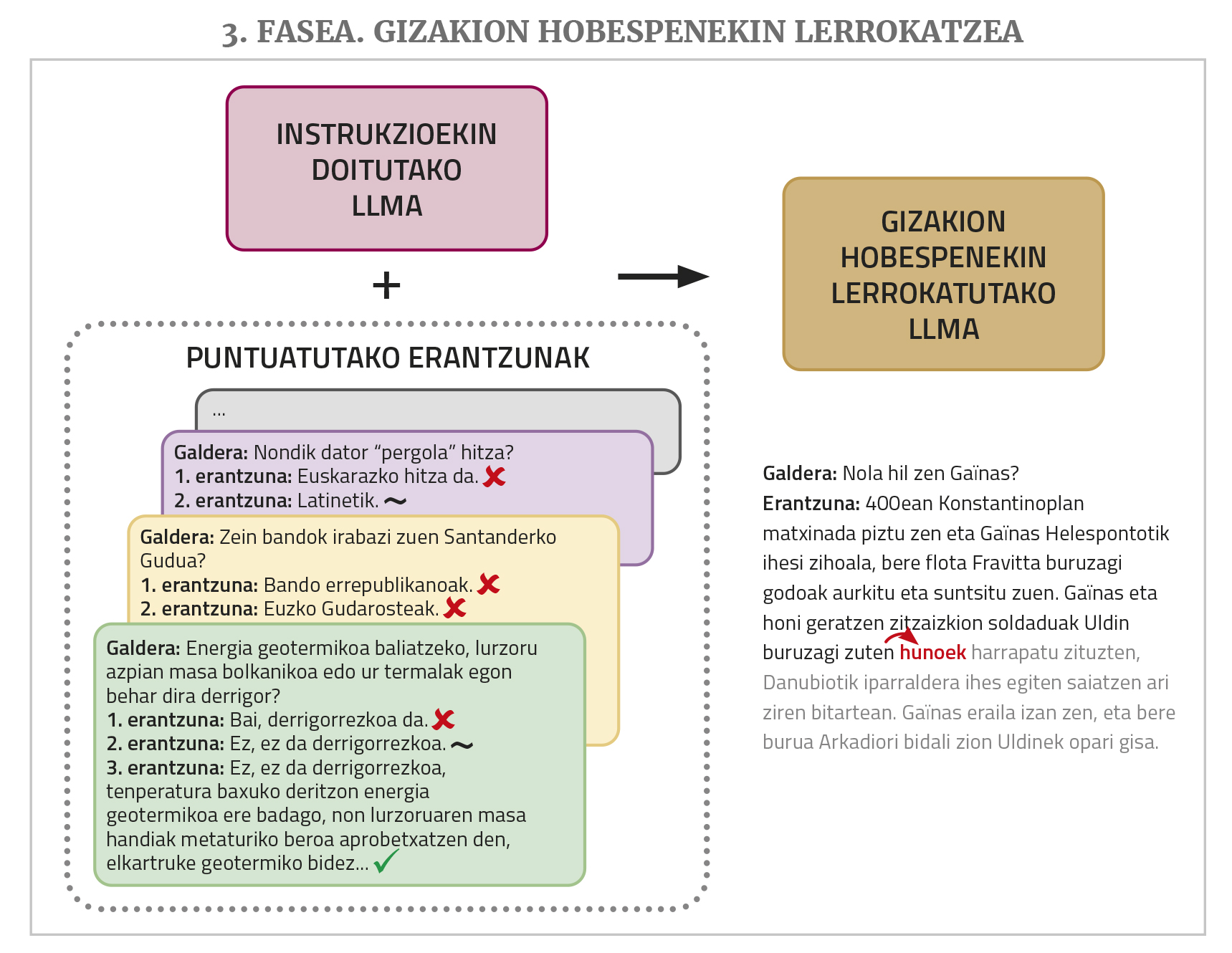
Construír un LLM en eúscaro desde cero, con todo, non é tarefa fácil. Para que funcionen ben, hai que adestrar con millóns de palabras, e en eúscaro non hai tantas. O número de textos que se pode conseguir coa tradución automática é suficiente, e con iso tamén realizamos probas piloto, pero os resultados non foron suficientes. Ademais, o adestramento completo destas xigantescas redes require máquinas moi potentes e tarda moitísimo. Por iso, é moi caro e, por tanto, inviable.
Por iso, a vía que habitualmente se utiliza é a de adoptar un LLM fundacional libre, previamente adestrado, e realizar un axuste fino ou un fine-tuning para que poida aprender mellor euskera. En definitiva, este axuste supón continuar co adestramento a través de textos en eúscaro, polo que tamén se lle denomina pre-adestramento continuado ou continual pre-training. Trátase de que o LLM que se ha pre-adestrado xa sabe que ten outros idiomas, que ten un coñecemento xeral e outras competencias, e que grazas á aprendizaxe por transferencia non necesita tanto tempo de texto ou adestramento para aprender eúscaro. Ademais, se se desexa, pódense utilizar técnicas como LoRA (Low-Rank Adaptation) para substituír toda a rede por unha banda, reducindo considerablemente as esixencias de memoria.
Nos últimos traballos neste camiño utilízase Chama desenvolvido pola empresa Meta e que foi cedida en licenza libre. O centro HiTZ da UPV/EHU, por exemplo, tomando como base Chama 2 e seguindo un adestramento coa colección de textos EusCrawl, sacou en xaneiro do ano pasado o LCM en euskera Latxa, que posteriormente, en abril, adaptou e mellorou cun corpus de texto maior. Latxa obtivo mellores resultados que calquera outro LLM nas probas de competencia en eúscaro (avaliado con probas preliminares de EGA) e nas preguntas ou tarefas xerais só superaba a GPT 4 (con conxuntos de avaliación preparados para preguntas xerais, de comprensión lectora e de preguntas de oposicións).
No noso centro de Tecnoloxías Orai NLP de Elhuyar, collemos a LLLaMa 3.1 e axustámola co corpus Zelai (Handi Orai Orai é a maior colección de textos libres en eúscaro recompilados por Zelai Orai, con 521 millóns de palabras), e o resultado é o de libre -eus-8B, presentado en setembro do ano pasado. Obtivo os mellores resultados en todos os tipos de tarefas entre os modelos fundacionais en eúscaro lixeiros (menos de 10 mil millóns de parámetros), e mesmo ofrece mellores resultados nalgunhas tarefas que os modelos moito máis grandes.
E os chatbots en eúscaro?
Á vista destes resultados, un pode pensar que xa temos unha especie de ChatGPT en eúscaro que creamos aquí. Pero como vimos, os resultados que obteñen os modelos locais para moitos tipos de solicitudes de tarefas en eúscaro aínda non alcanzan o nivel de GPT4, e sobre todo, os resultados son sensiblemente inferiores aos que se obteñen co inglés.
A razón diso explicámola arriba: A obtención dun chatbot funcional desde un LLM require tamén un axuste fino de instrucións e fases de adestramento para aliñalo coas preferencias humanas. Observouse que unha das principais causas do bo rendemento dos chatbot comerciais son as series de datos utilizadas nestes dous pasos, moi grandes e de calidade. E este tipo de datos (conxuntos de solucións de pedido e cuestionarios de resposta avaliados polas persoas), a diferenza dos textos que se poden obter da rede de pre-adestramento en cantidades relativamente elevadas de forma automática, esixen ser xerados manualmente polas persoas, o que resulta moi custoso. Os xigantes tecnolóxicos asígnanlle moito diñeiro e man de obra, e eses paquetes de datos non os deixan soltos. Non hai recursos suficientes para crear este tipo de cousas en eúscaro. Existen algúns conxuntos de datos libres deste tipo, pero non son o suficientemente grandes, non están en eúscaro, ... Mesmo sen un axuste de instrucións fino pódese conseguir que certas tarefas se fagan mellor cun ou varios exemplos da tarefa que se quere realizar na propia pregunta (esta técnica denomínase prompt engineering ou in-context learning), pero os resultados non son iguais aos que se obteñen co axuste.
Por todo iso, aínda queda moito traballo por facer para ter noso propio chatbot funcional. Iso non quere dicir que non o fagamos. No centro Orai, por exemplo, temos varios traballos en marcha. Por exemplo, máis aló do coñecemento do eúscaro e da resposta ás demandas xerais en eúscaro, analizamos se os LLM e os chatbots teñen coñecemento de Euskal Herria e da cultura vasca, creando e facilitando unha serie de datos para avalialo. O conxunto de datos está en inglés (á fin e ao cabo, os chats de grandes empresas funcionan mellor en inglés e queríase avaliar o coñecemento dos seus temas vascos, non a competencia en eúscaro) e fixéronse preguntas en inglés aos chatbot. A conclusión é que teñen un forte rumbo cultural e só acértanse de media ao redor do 20% das preguntas dos temas vascos. Probando diferentes técnicas en modelos fundacionais libres, tentamos melloralo e as sesións foron exitosas, cunha taxa de acerto que aumentou en torno ao 80%. O centro HiTZ tamén realizou un traballo similar e unha avaliación.
No centro Orai tamén traballamos o rumbo dos LLM en eúscaro. Traducimos ao euskera e adaptado ao contexto vasco o conxunto de datos BBQ que se utiliza para medir os rumbos da LLM, e fixémolo público coa licenza libre BasqBBQ. Medíronse os rumbos dos LLM en eúscaro (Latxa e Chama-eus-8b) e comparáronse cos do modelo Chama orixinal que os sustentan. E hase visto que os modelos adaptados ao eúscaro non teñen maior rumbo, senón todo o contrario.

Por último, tamén realizamos os primeiros experimentos sobre o requintado axuste das instrucións e a súa aliñación coas preferencias humanas. Para iso obtivéronse unha serie de conxuntos de datos en inglés libremente dispoñibles, tanto de instrucións (tipo de solucións de pedido) como de respostas puntuadas, e unha vez traducidas ao euskera mediante tradución automática, procedéronse a pasar estoutras dúas fases de adestramento ao noso modelo fundacional LLLaMa-eus-8B. Así, construímos o primeiro chatbot en eúscaro que pasou por todas as fases de adestramento. E comparamos os resultados co modelo de chat Chama de tamaño similar que Meta sacou cos seus datos privados, axustado ás instrucións e aliñado coas preferencias humanas, e habemos visto que o noso funciona moito mellor nesas tarefas creativas en eúscaro. Con todo, a calidade dos resultados aínda non chega ao modelo máis pecho como ChatGPT. Á fin e ao cabo, como xa se dixo, os conxuntos de datos abertos de instrución e adestramento de DPO non son tan grandes como os dos xigantes tecnolóxicos, e ademais, o feito de que sexan traducidos por tradución automática tamén ten certa influencia.
Todos estes traballos, e moitos máis, deberán ser realizados aínda para que se converta nun dos chatbot funcionais máis utilizados en eúscaro. Pero, mesmo cando se consegue, pode ser un problema polo a disposición da sociedade vasca. De feito, adestrar a estas xigantescas redes neuronais é tan caro como facelo, ter en marcha para poder utilizalas tamén é moi caro, xa que necesitan máquinas moi potentes. Os xigantes tecnolóxicos estadounidenses que ofrecen os chats comerciais máis exitosos están a perder unha enorme cantidade de diñeiro por estar na vangarda desta revolución e por gañar cota de mercado. Estes modelos non son rendibles e, por outra banda, o impacto ambiental deste tipo de máquinas grandes tamén está aí. Por iso, a optimización é tan importante como mellorar os resultados de todos estes bots, é dicir, obter os mesmos resultados utilizando redes neuronais máis sostibles económica e ecoloxicamente.
E precisamente por ese camiño vai a LLM de código aberto da empresa chinesa DeepSeek, coñecida a finais de xaneiro como DeepSeek-V3. As descargas da APP para o seu uso superaron as de ChatGPT en Estados Unidos, xa que ofrecía resultados comparables coas súas a un prezo moito máis barato. Isto provocou un terremoto nas cotizacións bolsistas das empresas estadounidenses AA e chip e nas expectativas e expectativas de futuro. Pero ademais da gran calidade dos resultados, o feito é que, obrigados polo embargo dos chips que China puxo a disposición de Estados Unidos, as LLM tiveron que buscar vías para poder desenvolverse en chips menos potentes.
Aproveitando algunhas variantes que até agora non foron utilizadas polos demais na estrutura e adestramento da LLM, a empresa afirma que o custo do adestramento de DeepSeek-V3 foi do 6% do GPT-4 e que só requiriu o 10% da enerxía do adestramento de LLLaMa 3.1. O custo de ofrecer o modelo como servizo é moito menor, polo que se di que é o único que non perde diñeiro, aínda que se ofrece máis barato. É dicir, os resultados de DeepSeek son similares aos modelos máis pechos como ChatGPT, mellores que os de código aberto como Chama, é de código aberto e ten menos da décima parte da necesidade enerxética (e por tanto de custo) dos outros modelos. Pronto se verá si confírmase a idoneidade deste camiño, se os desarrolladores doutros modelos tamén o toman, e tamén nos serve para desenvolver e ofrecer modelos propios en eúscaro dunha maneira máis rápida e económica.
