

Small virtual brains
2015/06/01 Azkune Galparsoro, Gorka - Ikertzailea eta irakasleaEuskal Herriko Unibertsitateko Informatika Fakultatea Iturria: Elhuyar aldizkaria

Large projects underway
The world's greatest powers have already begun the study of the brain with great projects. On the one hand, there are two projects that receive public funds: BRAIN Initiative from USA and Human Brain Project from Europe. Both projects have different perspectives: Americans seek to obtain a specific brain map, analyzing well the functioning of each neuron; Europeans, for their part, have a more computer vision, which aims to achieve a specific computational model of our brain, to develop virtual brains.
There is also private money. With much more practical goals, Google, Microsoft, Baidu (Google China), Facebook and other large companies have created their own research projects. Given the nature of these companies, it is immediately detected that the vision is very “computer”: it is based on the human brain to artificially imitate our intelligence and thus offer much more intelligent services.

This article aims to make known the innovative concept that is at the center of the projects of these large companies: deep learning. This concept takes to another level the artificial neural networks that were invented in the 60s and 70s of the last century. In 2006 researcher Geoffrey Hinton published the foundations of deep learning. Hinton is currently working on Google.
Artificial neural networks
The first stop of this trip is on artificial neural networks. Like the human brain, these artificial networks are based on neurons. Each neuron has inputs and output. Both inputs and outputs are only numbers. Therefore, the work of a neuron is to take the inputs and calculate an output using simple mathematical functions. Neurons are organized in networks forming layers. Normally there is an input layer. If we made a comparison with our brain, the input layer would be used to collect sensitive information. Below are hidden layers and finally exit layer (for example, neurons that send signals to our muscles). Figure 1 shows a simple structure of it.
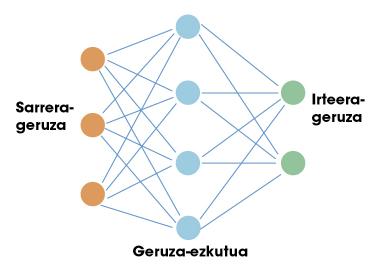
Success of neural networks in the field of artificial intelligence. The key is in the theorem of universal approximation. Some mathematicians demonstrated that a neuronal network with a single hidden layer can approach any nonlinear function. In other words, a neural network can learn any possible relationship between input and output numbers. In the case of a human being, he can learn any reaction related to the information the senses receive. There is precisely the potential of these networks.
Is a single layer enough?
Theoretically you can learn any relationship with a hidden layer, but in practice such simple networks are not very useful for complex tasks. For example, suppose we want to distinguish faces from lots of images. The input to the network would be an image and output a face or not in that image. Because of the complexity of input information (in short, an image is a lot of numbers), single-layer networks do not achieve very satisfactory results. Researchers have to work hard on images, performing some processing and calculating some geometric characteristics, to provide the network with less and more significant information (Figure 2). Thus, neural networks well separate the faces.
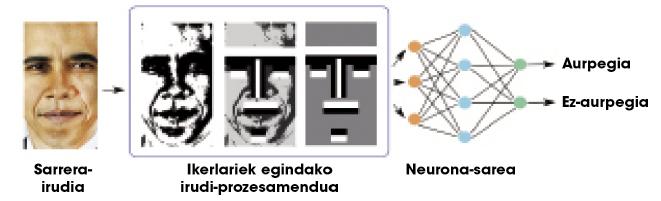
Our brain performs all the calculations corresponding to any task in the neural network itself, that is, there are no external researchers who perform the processing of Figure 2. To do this, our brain is organized into a lot of neural layers. Therefore, some researchers thought that instead of using a single hidden layer, many layers might have to be used to cope with complex tasks. Neural networks with many layers are called “deep nets.”
Deep network training problems
For a neural network to work properly it is necessary to train. In the case of figure 2 that we have just seen, before asking the network for the separation of faces, you have to show a lot of images indicating which are the faces and which are not. In this way, the network learns the parameters of each of its neurons to correctly perform this specific task, that is, the nonlinear function that we said initially is concretized in the training phase to relate the input data to the outputs.

Applying training techniques in single-layer networks in deep networks, the results were very bad: deep networks learned nothing. They soon realized that there were great shortcomings in training techniques. They could not understand how a deep network entered. Therefore, until 2006 the networks of more than two hidden layers were not even used, since they could not be trained.
What happened in 2006? Geoffrey Hinton created with his team a revolutionary technique to train deep networks. It was a deep learning, deep learning, newborn.
Google Brain amazing

One of the most surprising examples of the use of deep learning is Google Brain. As shown in figure 4, it uses 1000 computers to keep a deep network running. In an article published in 2013, a group of Google researchers unveiled a big step forward. Taking advantage of the ability of Google Brain, they trained for three days a deep network with surprising and curious results.
As we said before, to learn to differentiate a face you have to pass a training phase in which you give a lot of images to the network and you are told in which image the faces appear and in which image they do not. This process is called “supervised learning.” According to some neuroscientists, humans do not learn to differentiate faces, but, as we often see faces, our brain learns a face model, without anyone saying that model is a face. That is, learning is not supervised.
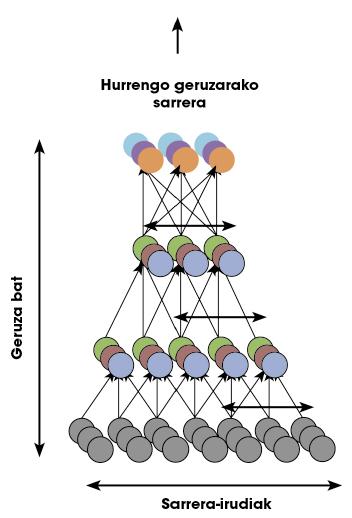
Google researchers joined these theories and asked: “Is it possible for a deep network to unsupervised learn what a face is?” To answer the question, they created a deep network based on the structure of the human brain. The network has a billion parameters to train. Although it is terrible, the visual cortex of a human being has only 100 times more neurons and synapses! Figure 5 shows a representation of the network.
The researchers justified that in the videos that are on Youtube appear a lot of human faces. Therefore, if we randomly select a lot of videos and use the images to train the network, the network should learn the one-sided model. Say and do. After three days of training, they showed the network images with faces. In very high percentages (81.7%), the network responded to these images with the same activation pattern. In images where no faces appeared, it showed no such activation. I meant that the network knew what a face was.
Through advanced representation techniques, activation patterns can become spectacular geometric features. The researchers used these techniques to represent the face model that the network had “saved”. Figure 6 shows a terrible appearance.
As you know, on Youtube cats and humans appear on many occasions. It is logical to think, therefore, that the net would also study what a cat is. To solve the doubt, the researchers collected images of cats and passed them to the network. And yes, the network showed activation patterns similar to those of the faces. Here is the cat model that the net learned (figure 7).

Why do deep networks work so well? It seems that the reason is its hierarchical structure. Neurons have the ability to save abstract models of information from the bottom layer by layer, from color differences between pixels of an image (first layer) to geometric characteristics (last layers). In addition, all these features and models can learn their case according to the data provided.
And now what?
This work we have just presented was published in 2013, “yesterday”. Deep Learning remains a very “young” field and therefore has a great future. For example, there is a well-known database with lots of images, ImageNet, in which object separation contests are organized into images. Google was the last winner. This database has experimentally calculated that humans have a 5.1% error rate. Chinese company Baidu has recently published a 5.98% error rate with deep learning, although it has not yet been officially demonstrated.

Deep learning is getting very good results in the understanding of natural languages and visual tasks, two of the most important capabilities we humans have. Work has been carried out based on neurosciences, although the models used are not yet very precise. Surely the contributions of the Human Brain Project and BRAIN Initiative projects will teach us new ways. At some point, advances in neuroscience and artificial intelligence will find themselves creating more powerful virtual brains. Who knows...
Bibliography

