

Petits cerveaux virtuels
2015/06/01 Azkune Galparsoro, Gorka - Ikertzailea eta irakasleaEuskal Herriko Unibertsitateko Informatika Fakultatea Iturria: Elhuyar aldizkaria

Grands projets en cours
Les plus grandes puissances du monde ont déjà commencé l'étude du cerveau avec de grands projets. D'une part, il convient de noter deux projets qui reçoivent des fonds publics: BRAIN Initiative des USA et Human Brain Project d'Europe. Les deux projets ont des perspectives différentes: les Américains cherchent à obtenir une carte du cerveau concret, en analysant bien le fonctionnement de chaque neurone; les Européens, quant à eux, ont une vision plus informatique, qui vise à obtenir un modèle informatique concret de notre cerveau, pour développer des cerveaux virtuels.
Il y a aussi de l'argent privé. Avec des objectifs beaucoup plus pratiques, Google, Microsoft, Baidu (Google Chine), Facebook et autres grandes entreprises ont créé leurs propres projets de recherche. Compte tenu de la nature de ces entreprises, on constate immédiatement que la vision est très « informatique » : elle est basée sur le cerveau humain pour imiter artificiellement notre intelligence et offrir ainsi des services beaucoup plus intelligents.

Cet article vise à faire connaître le concept innovant qui est au centre des projets de ces grandes entreprises: la deep learning (apprentissage profond). Ce concept porte à un autre niveau les réseaux neuronaux artificiels qui ont été inventés dans les années 60 et 70 du siècle dernier. En 2006, le chercheur Geoffrey Hinton a publié les bases de la deep learning. Hinton travaille actuellement sur Google.
Réseaux neuronaux artificiels
Le premier arrêt de ce voyage est sur les réseaux neuronaux artificiels. Comme le cerveau humain, ces réseaux artificiels sont basés sur des neurones. Chaque neurone a des entrées et une sortie. Les entrées et les sorties ne sont que des nombres. Le travail d'un neurone consiste donc à prendre les entrées et à calculer une sortie en utilisant pour cela des fonctions mathématiques simples. Les neurones sont organisés en réseaux formant des couches. Il y a normalement une couche d'entrée. Si nous faisions une comparaison avec notre cerveau, la couche d'entrée serait utilisée pour recueillir des informations sensibles. Ensuite, des couches cachées sont placées et enfin la couche de sortie (par exemple, neurones qui envoient des signaux à nos muscles). Dans la figure 1, vous pouvez voir une structure simple de celui-ci.
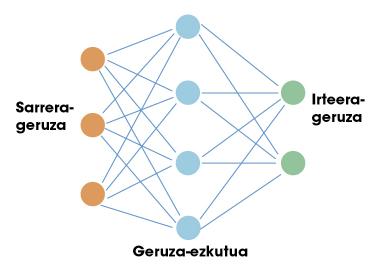
Succès des réseaux neuronaux dans le domaine de l'intelligence artificielle. La clé est dans le théorème de l'approche universelle. Certains mathématiciens ont montré qu'un réseau neuronal avec une seule couche cachée peut approcher n'importe quelle fonction non linéaire. En d'autres termes, un réseau neuronal peut apprendre toute relation possible entre les numéros d'entrée et de sortie. Dans le cas d'un être humain, vous pouvez apprendre toute réaction liée à l'information que les sens reçoivent. Voilà précisément le potentiel de ces réseaux.
Une seule couche est-elle suffisante ?
Théoriquement on peut apprendre n'importe quelle relation avec une couche cachée, mais en pratique les réseaux si simples ne sont pas très utiles pour des tâches complexes. Par exemple, supposons que nous voulons distinguer les visages d'un tas d'images. L'entrée au réseau serait une image et la sortie un visage ou non sur cette image. En raison de la complexité des informations d'entrée (en bref, une image est beaucoup de nombres), les réseaux d'une couche n'atteignent pas des résultats très satisfaisants. Les chercheurs ont beaucoup à travailler sur les images, en procédant à des traitements et en calculant certaines caractéristiques géométriques, pour fournir au réseau une information moindre et plus significative (figure 2). Ainsi, les réseaux neuronaux séparent bien les visages.
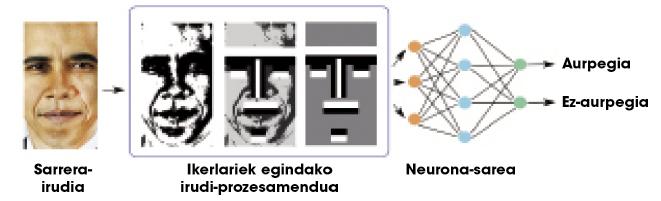
Notre cerveau effectue tous les calculs correspondant à n'importe quelle tâche dans le réseau neuronal lui-même, c'est-à-dire qu'il n'y a pas de chercheurs externes qui effectuent le traitement de la figure 2. Pour ce faire, notre cerveau est organisé dans beaucoup de couches neuronales. Par conséquent, certains chercheurs ont pensé qu'au lieu d'utiliser une seule couche cachée, il faudrait peut-être utiliser plusieurs couches pour faire face à des tâches complexes. Les réseaux neuronaux avec beaucoup de couches sont appelés «réseaux profonds».
Problèmes d'entraînement en réseau profond
Pour qu'un réseau neuronal fonctionne correctement, il est nécessaire de former. Dans le cas de la figure 2 que nous venons de voir, avant de demander au réseau la séparation des visages, il faut montrer beaucoup d'images indiquant quels sont les visages et ce n'est pas. De cette façon, le réseau apprend les paramètres de chacun de ses neurones pour accomplir correctement cette tâche concrète, c'est-à-dire que la fonction non linéaire que nous disions initialement se concrétise dans la phase d'entraînement pour relier les données d'entrée aux sorties.

En appliquant des techniques d'entraînement en réseaux monocouches en réseaux profonds, les résultats étaient très mauvais : les réseaux profonds n'apprenaient rien. Ils ont vite réalisé qu'il y avait de grandes lacunes dans les techniques de formation. Ils ne pouvaient pas comprendre comment un réseau profond entrait. Ainsi, jusqu'en 2006, les réseaux de plus de deux couches cachées n'étaient même pas utilisés car ils ne pouvaient pas être formés.
Que s'est-il passé en 2006? Geoffrey Hinton a créé avec son équipe une technique révolutionnaire pour former des réseaux profonds. C'était un apprentissage profond, deep learning, nouveau-né.
Google Brain étonnant

Google Brain est l'un des exemples les plus surprenants de l'utilisation du deep learning. Comme on le voit dans la figure 4, il utilise 1000 ordinateurs pour maintenir un réseau profond en fonctionnement. Dans un article publié en 2013, un groupe de chercheurs de Google a publié un grand pas en avant. Profitant de la capacité de Google Brain, ils ont formé pendant trois jours un réseau profond avec des résultats aussi étonnants que curieux.
Comme nous l'avons déjà dit, pour apprendre à différencier un visage, il faut passer une phase d'entraînement où l'on donne beaucoup d'images au réseau et on lui dit sur quelle image les visages apparaissent et sur quelle image il n'est pas. Ce processus est appelé «apprentissage supervisé». Selon certains neuroscientifiques, les êtres humains n'apprennent pas ainsi à différencier les visages, mais, comme nous voyons souvent les visages, notre cerveau apprend un modèle de visage, sans que personne ne dise que ce modèle est un visage. Autrement dit, l'apprentissage n'est pas supervisé.
Les chercheurs de Google ont rejoint ces théories et ont demandé: Pour répondre à la question, ils ont créé un réseau profond basé sur la structure du cerveau humain. Le réseau a un milliard de paramètres pour former. Même si c'est terrible, la croûte visuelle d'un être humain n'a que 100 fois plus de neurones et de synapses ! Dans la figure 5, vous pouvez voir une représentation du réseau.
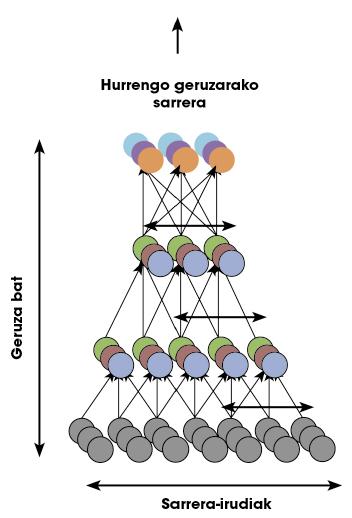
Les chercheurs ont justifié que dans les vidéos qui sont sur Youtube apparaissent beaucoup de visages humains. Par conséquent, si nous sélectionnons aléatoirement beaucoup de vidéos et utilisons les images pour former le réseau, le réseau devrait apprendre le modèle d'un côté. Dire et faire. Après trois jours d'entraînement, des images coûteuses ont été montrées au réseau. En pourcentage très élevé (81,7%), le réseau répondait à ces images avec le même motif d'activation. Dans les images où les visages n'apparaissaient pas, je n'ai montré aucune activation de ce type. Je voulais dire que le réseau savait ce qu'était un visage.
Grâce à des techniques avancées de représentation, les motifs d'activation peuvent devenir des caractéristiques géométriques spectaculaires. Les chercheurs ont employé ces techniques pour représenter le modèle de visage que le réseau a eu « gardé ». Dans la figure 6, vous pouvez voir un résultat d'apparence terrible.
Comme vous le savez, sur Youtube apparaissent souvent des chats en plus des humains. Il est donc logique de penser que le réseau étudierait également ce qu'est un chat. Pour résoudre le doute, les chercheurs ont recueilli des images de chats et les ont transmis au réseau. Et oui, le réseau montrait des motifs d'activation similaires à ceux des visages. Voici le modèle de chat qui a appris le réseau (Figure 7).

Pourquoi les réseaux profonds fonctionnent-ils si bien ? Il semble que la raison est sa structure hiérarchique. Les neurones ont la capacité d'enregistrer des modèles abstraits de l'information de la couche inférieure par couche, des différences de couleur entre les pixels d'une image (première couche) aux caractéristiques géométriques (dernières couches). En outre, toutes ces fonctionnalités et modèles peuvent apprendre à votre cas selon les données qui vous sont fournies.
Et maintenant ?
Ce travail que nous venons d’exposer a été publié en 2013, “hier”. Le Deep Learning reste un domaine très « jeune » et a donc un grand avenir. Par exemple, il existe une base de données bien connue avec beaucoup d'images, ImageNet, dans laquelle des concours de séparation des objets sont organisés en images. Google a été le dernier vainqueur. Cette base de données a calculé expérimentalement que les humains ont un taux d'erreur de 5,1%. La société chinoise Baidu a récemment publié un taux d'erreur de 5,98% avec le deep learning, bien qu'il n'ait pas encore été officiellement démontré.

La deep learning obtient de très bons résultats dans la compréhension des langages naturels et dans les tâches visuelles, deux des capacités les plus importantes que nous avons les humains. Des travaux basés sur les neurosciences ont été réalisés, bien que les modèles utilisés ne soient pas encore très précis. Sûrement les contributions des projets Human Brain Project et BRAIN Initiative nous enseigneront de nouvelles voies. À un moment donné, les progrès en neuroscience et en intelligence artificielle vont créer des cerveaux virtuels plus puissants. Qui sait...
Bibliographie Bibliographie

