

Mapes virtuals d'idiomes
2018/09/01 Artetxe Zurutuza, Mikel - Hizkuntzaren prozesamenduan doktoregaia EHUn Iturria: Elhuyar aldizkaria
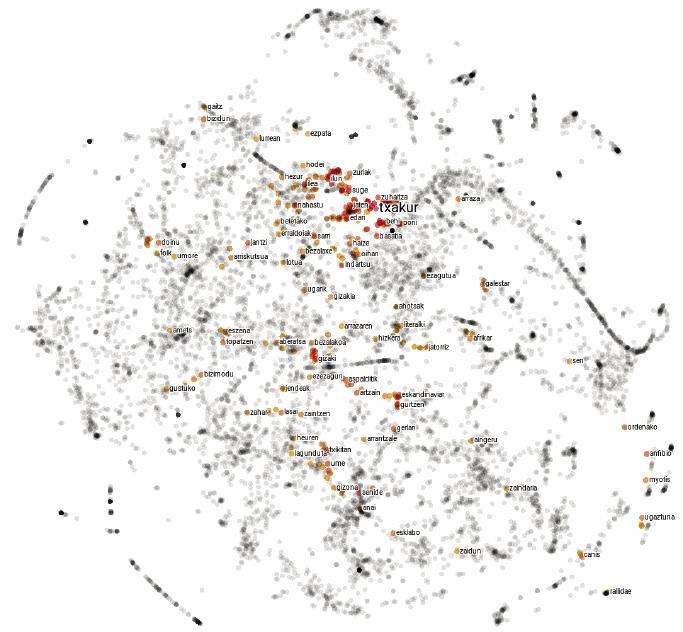
És curiós l'idioma. Tant en l'escriptura com en la pronunciació, les paraules porc i polls són molt similars, mentre que les paraules porc i senglar són completament diferents. Entre els animals, no obstant això, els porcs estan molt més prop dels senglars que dels polls. En definitiva, la relació entre les paraules d'una llengua i els seus significats és arbitrària, i les relacions entre els conceptes de porc, poll i senglar només viuen en la nostra ment.
No obstant això, en fer una cerca en Google o parlar amb Siri, la qual cosa tenim tan interioritzat es converteix en una gran dificultat per a les màquines. I igual que quan ens perdem en la muntanya o en la carretera, les màquines utilitzen mapes per a avançar en el laberint de llengües. Aquests mapes es denominen Embedding i, a través d'ells, el processament del llenguatge s'ha internalitzat en terrenys que semblaven impensables. Farem aquest viatge pas a pas.
De mapes de ciutats a mapes de paraules
Abans d'endinsar-nos en el territori de la llengua, parem momentàniament per a fixar-nos en els nostres mapes comuns. Bàsicament, els mapes que coneixem són representacions gràfiques d'un territori, per exemple, que assignen un punt a cada ciutat en cada cas. Lògicament, perquè els mapes tinguin sentit, aquests punts no estan dispersos de qualsevol manera, sinó que la ubicació del mapa respecta les distàncies que tenim en la realitat. Així, en un mapa, París ens apareixerà més prop de Brussel·les que de Moscou, perquè en la realitat la capital francesa està més prop de la belga que de la russa.
Els mapes d'idiomes no són molt diferents. En lloc d'explicar les ciutats, cada punt representa una paraula i les distàncies entre elles depenen de la semblança semàntica de les paraules. Per tant, en un mapa d'aquest tipus, el punt corresponent a la paraula porc estarà més prop del corresponent al senglar que al poll, ja que la similitud semàntica entre les paraules porc i senglar és major que entre les paraules porc i polls.
Però no tot és tan senzill: per a captar correctament la complexitat del llenguatge, les 2 dimensions del paper es queden curtes, i aquests mapes normalment tenen unes 300 dimensions. Però que no t'espantin els grans números! Com hi ha un salt d'una sola dimensió de la recta a les dues dimensions del quadrat, i un salt de les dues dimensions del quadrat a les tres del cub, pots imaginar que existeix un salt semblant des de les tres dimensions del cub a les quatre de la tenacitat, i així podríem seguir fins a arribar a les 300 dimensions citades.
Però com construir un mapa de 300 dimensions si vivim en tres dimensions? No et preocupis, no començarem! En realitat, aquests mapes no són físics sinó objectes matemàtics que viuen en la memòria dels ordinadors. De fet, tots els mapes poden ser reproduïts mitjançant números. Per a això se sol consensuar un sistema de referència, indicant cada punt en funció de la seva posició respecte als diferents eixos. Així, segons la distància angular respecte a l'equador i al meridià de Greenwich, les coordenades de París (48.86, 2.35) són les de Brussel·les (50.85, 4.35) i Moscou (55.75, 37.62). Aquestes coordenades ens permeten, entre altres coses, calcular matemàticament les distàncies entre ciutats. El mateix es fa amb els mapes d'idiomes, però com en lloc de tenir 2 dimensions, són necessaris 300 números per a descriure cada punt. Perquè cadascuna d'aquestes seqüències de números que representen una paraula és el que anomenem embedding.
Partint del text i cartografiant les màquines
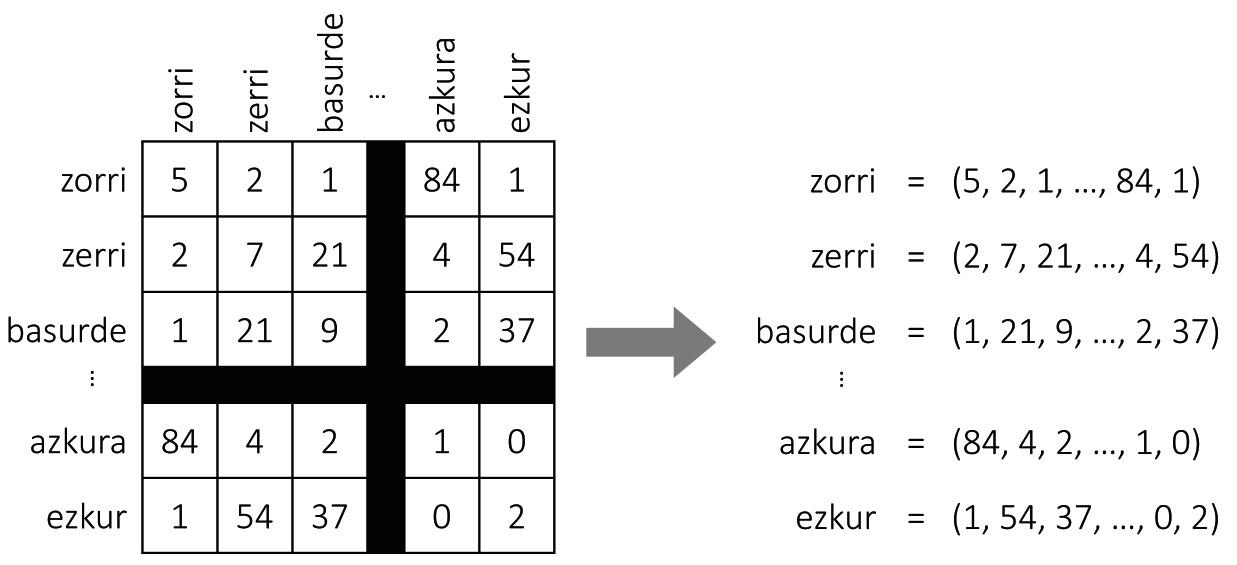
La realització de mapes és un treball laboriós. Els cartògrafs recopilen i analitzen diverses fotografies, mesuraments i estadístiques, i elaboren representacions gràfiques que coincideixen amb aquestes dades. La descripció de les llengües també ha estat realitzada per l'home: aquí estan, entre altres, els diccionaris que ens són tan comuns. Però els mapes que ens ocupa no són manuals. Analitzant textos llargs, les màquines les creen automàticament i és una recepta senzilla i eficaç.
Com es mostra en la Figura 2, suposem que construïm una taula gegant amb totes les paraules d'una llengua. Per a cada paraula tindrem una fila i una columna, de manera que cada cel·la s'adapti a un parell de paraules. Per a emplenar la taula, prendrem un text llarg i comptarem el nombre de frases que apareixen simultàniament cada parella de paraules. I voilà, tenim el nostre mapa! Per a cada paraula agafarem la llista de números de la fila corresponent, que seran les coordenades de la paraula.
Encara que sembli mentida, aquesta simple aproximació genera mapes bastant assenyats. De fet, segons la hipòtesi distributiva de la semàntica [8, 7], paraules similars solen tenir patrons de representació similars, per la qual cosa el procediment anterior els assignarà coordenades similars. També per al nostre exemple inicial, les paraules senglar o porc apareixeran amb freqüència al costat de la paraula gla i poques vegades al costat de la paraula picor, i amb la paraula zorri ocorrerà a l'inrevés. Per tant, els porcs i taulells tindran unes coordenades similars i quedaran pròxims entre si en el mapa. Les coordenades dels polls seran bastant diferents, per la qual cosa s'allunyarà d'elles.
Però hi ha alguna cosa que falta en aquesta recepta. I és que, encara que les 300 dimensions esmentades anteriorment semblaven molt, aquest procediment generaria mapes de desenes de milers de dimensions, ja que els idiomes formaran les seves coordenades amb tantes paraules com números. Com reduir el nombre de dimensions? La resposta no ens és molt estranya: els nostres mapes comuns solen tenir dues dimensions, encara que en la realitat es parla d'un món tridimensional. De fet, a l'hora de crear mapes, sol excloure's la dimensió de l'altura, ja que no és molt significativa a l'hora de calcular distàncies entre ciutats. Alguna cosa semblança es fa amb els mapes de les llengües: utilitzant diferents tècniques matemàtiques s'identifiquen els eixos de major variabilitat (els més significatius) i s'exclouen del mapa la resta de dimensions. Malgrat algunes adaptacions per a corregir l'efecte de la freqüència, aquesta és la idea bàsica que subjeu en les tècniques de comptatge per a l'estudi de les embeddings [3]; tingui's en compte que les tècniques basades en l'aprenentatge automàtic [11, 4] segueixen el mateix procediment de manera implícita [10].
Jugant amb mapes
Malgrat la seva senzillesa, els nostres mapes comuns oculten més secrets del que en principi sembla. Encara que no han estat pensats per a això, també serveixen per a apreciar, per exemple, la temperatura que es produeix en qualsevol part del món. De fet, els punts que es troben en latituds extremes, els més pròxims als pols, solen ser més freds, mentre que els punts més pròxims a l'equador són més calorosos. Així com l'eix de la latitud es relaciona amb la temperatura, en els mapes de les llengües també es poden identificar eixos similars que relacionen la polaritat de les paraules (grau de positivitat i negativitat) amb altres característiques [12]. Gràcies a ells, les aplicacions d'anàlisi automàtica d'opinions han adquirit gran força en els últims temps.
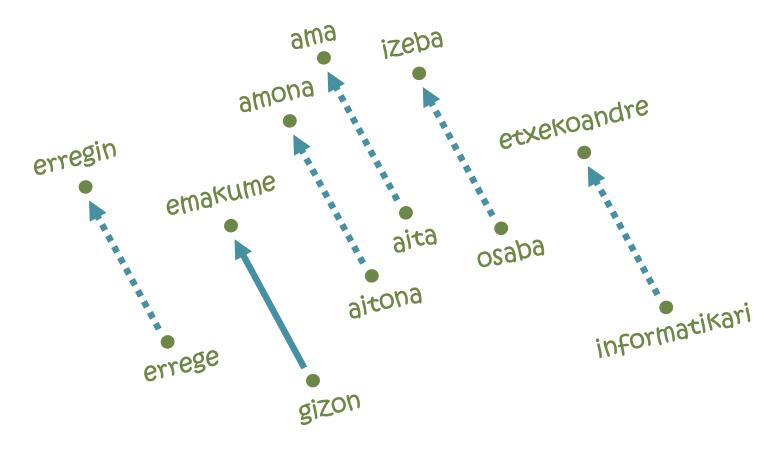
Però el que ha fet les embeddings tan populars ha estat la resolució d'analogies [11]. La idea no pot ser més senzilla: Per a anar des de París a Brussel·les és necessari recórrer 222 km al Nord i 144 km a l'est; així mateix, en cadascun dels eixos del mapa de la llengua es necessitarà una certa distància des de la paraula home fins a la paraula dona, per exemple. Perquè si comencem per la paraula rei i seguim els mateixos passos, arribem a la paraula erregin! De fet, la trajectòria estudiada codifica la relació home-dona i la trasllada al seu equivalent femení a partir de qualsevol paraula masculina. Anàlogament, es poden realitzar analogies equivalents per a les relacions pais-capital, singular-plural, present i passat.
Però no tot és tan bonic: si comencem per la paraula informàtica seguint la mateixa trajectòria d'homes i dones, per exemple, arribaríem a parlar de mestresses de casa [5]. En altres paraules, segons el mapa, la informàtica és cosa d'homes, i les tasques domèstiques són de dones. Què veure, aprendre allò: les embeddings es basen en textos escrits per éssers humans i reflecteixen les mateixes tendències discriminatòries arrelades en la nostra societat. De fet, segons diversos experts, afrontar aquest tipus de comportaments injustos serà un dels reptes futurs de la intel·ligència artificial.
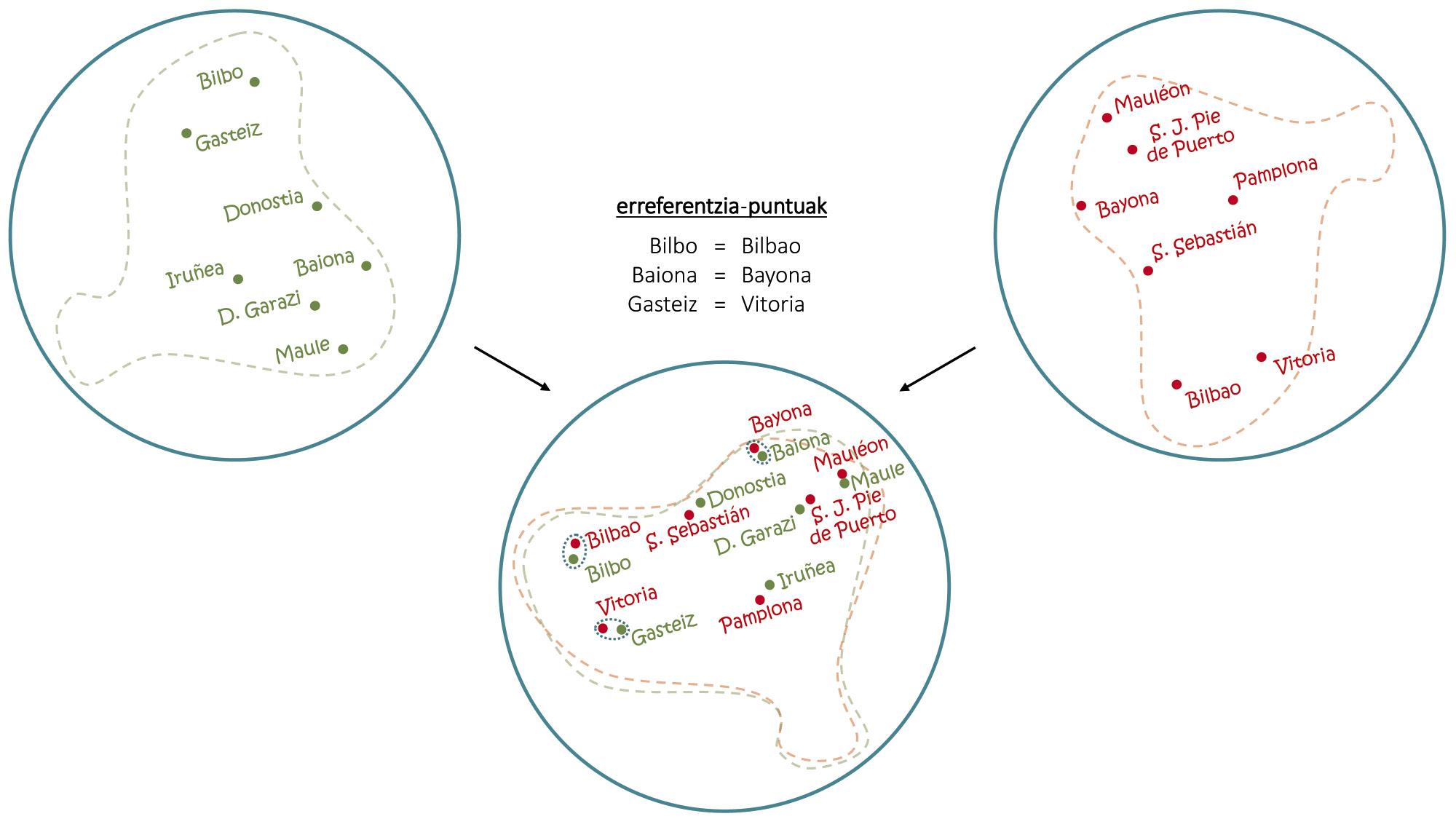
Malgrat els problemes, si amb una sola llengua es poden fer aquests trucs, combinant mapes de diversos idiomes s'han aconseguit coses encara més sorprenents. Tal com s'observa en la figura 4, igual que amb la superposició de sengles mapes en basc i en castellà es poden extreure les contraprestacions en castellà de les capitals basques, amb les embeddings s'utilitza el mateix principi bàsic per a induir traduccions de paraules comunes [1, 6]. En aquest sentit, recentment s'han desenvolupat traductors automàtics capaços d'aprendre sense cap mena de conducció humana [2, 9], de llegir textos llargs en diversos idiomes i de realitzar traduccions entre ells sense altres ajudes.
Noves destinacions
Encara que el nostre viatge està a punt d'arribar al final, el camí recorregut per les embeddings sembla infinit. Al costat de la millora de les tècniques d'estudi i el desenvolupament de noves aplicacions, els intents d'abordar frases o textos més llargs a partir de mapes de paraules han cobrat força en els últims temps. Fins a on ens portarà aquest camí, però no apareix en cap mapa i, amb noves metes en l'horitzó, el futur no podia ser més emocionant.
Referències
Treball presentat als premis CAF-Elhuyar.

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia

