Informática genética
2010/03/01 Roa Zubia, Guillermo - Elhuyar Zientzia Iturria: Elhuyar aldizkaria

No conocemos sistemas más eficientes que la vida. Sin embargo, la mayor parte de nuestra tecnología está basada en sistemas sin vida. Por supuesto, la razón es que la vida, para ser eficaz, está basada en un sistema muy complejo y que la generación de tecnología compleja es muy difícil. Pero tal vez no lo hagamos nosotros. Los sistemas vivos pueden hacerlo para nosotros.
Es fácil de decir, pero no es tan fácil de conseguir. Por ejemplo, es difícil convencer a los sistemas vivos de que elaboren los componentes de los ordenadores. Hay científicos que lo están haciendo y es difícil. Hay buenas ideas en marcha. Podríamos hacer chips de ADN, que es el refugio de información en los seres vivos y, por tanto, ¿por qué no será el lugar adecuado para guardar la información informática?
El primer paso para conseguirlo es controlar la corriente eléctrica dentro del ADN. Pero la naturaleza eléctrica del ADN no ha sido revelada por los científicos. Según un estudio de hace diez años, es aislante; según otro de la misma época, tiene la capacidad de conducir moléculas cargadas; y otros investigadores propusieron que el movimiento de las proteínas que leen ADN se debe a la electricidad. De todo.
Sin embargo, la mayor parte de estos estudios se han centrado en las interacciones entre las bases del ADN, es decir, en la interacción eléctrica que une ambas hélices. Pocos han estudiado, sin embargo, la capacidad de los electrones para moverse por el eje de la cadena del ADN; si pueden moverse como en un cable o no.
La respuesta es que sí, según han concluido investigadores de la Agencia Japonesa de la Energía Atómica. Mediante la excitación de un electrón de un átomo de fósforo, se deslocaliza en la cadena del ADN y rápidamente, mil veces más rápido que en las bases. Este movimiento de electrones puede ser imprescindible en el mecanismo que corrige los errores del ADN. El hombre también podría aprovecharlo, ¿por qué no?
Datos y datos
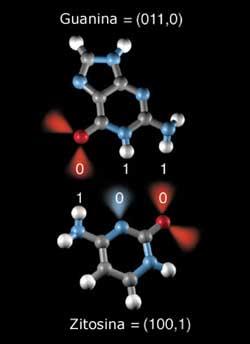
Supongamos que controlamos la electricidad interna de la molécula de ADN y que podemos diseñar transistores y circuitos electrónicos a partir de dicha molécula como materia prima. Esto nos permite codificar mucho 0 y 1. Mucho. La propia célula la utiliza para ello. Es más, como hay cuatro bases, tiene más de dos opciones, ¡puede codificar los números 0, 1, 2 y 3! Por tanto, el uso electrónico del ADN permitiría codificar más datos de los habituales. Sin embargo, esto no es necesariamente bueno.
Por ejemplo, el aumento y abaratamiento de las memorias ha generado nuevos problemas en la informática. La propia programación ha cambiado mucho. Los programadores iniciales hacían cosas increíbles para ahorrar hasta un bit en el código. El programa no podía albergar una gran memoria. Por ello, utilizaban lenguajes de muy bajo nivel y tenían un control absoluto sobre cada bit citrin que entraba y salía en los registros en cada momento (en cada ciclo del procesador). Funcionaban con los números 0 y 1, pensaban en la aritmética binaria.
Pero cuando no hay que ahorrar memoria, la programación no es así. Se utilizan lenguajes de alto nivel, es decir, que el procesador no entiende directamente. El proceso de comprensión para el procesador genera un código repetitivo y no refinado. Los programas funcionan, pero tienen muchos códigos, por decirlo de alguna manera, sobran.
Y puede que ocurra algo parecido con el material genético. El ADN también tiene capacidad para almacenar mucha información. Si se utiliza en las memorias de los ordenadores, sería un buen lugar para acumular mucha información sobrante.
En la naturaleza es así. A lo largo de la evolución se han ido acumulando muchos códigos genéticos en los cromosomas humanos: parte de ellos fueron cedidos por bacterias y virus, parte por la duplicación de genes o por errores en la autofcopia de células. Hay muchas maneras de explicar en un genoma la información genética adicional. Todo ello hace que el genoma conserve mucha información sobre sobra. Las secuencias de los genes están intercaladas con partes que no codifican nada, y que son precisamente las partes (intrones) que la célula elimina antes de empezar a fabricar proteínas.
Es cierto que todavía no conocemos toda la información que codifica el genoma. Los científicos al principio creían que las partes que no codificaban las proteínas no codificaban información, y al conjunto de estas partes se le llamó DNA basura. Sin embargo, en algunas de estas partes se ha descubierto que, por ejemplo, hay zonas de activación de genes. No todo el DNA basura es basura.
Sin embargo, el genoma de los seres vivos no es el sistema matemático perfecto que codifica la información. Al igual que el software escrito con lenguaje de alto nivel, no tiene la mayor eficacia que puede tener. Tiene partes repetitivas y toda la información que codifica no es imprescindible para formar un ser vivo.
Y quizá esa sea una de las grandes asignaturas que hay que aprender de la genética y de la informática: en una colección de muchos datos, algunos de ellos sobran.

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia