

Resolent els foscos camins de la intuïció
2017/05/12 Azkune Galparsoro, Gorka - Ikertzailea eta irakasleaEuskal Herriko Unibertsitateko Informatika Fakultatea Iturria: Elhuyar aldizkaria

Entorn de la intuïció, molts pensadors han treballat al llarg de la història, com Descartes, Kant o Husserl. Avui dia, no obstant això, la intuïció és un concepte que estudien psicòlegs i neuròlegs, utilitzant per a això les eines i camins de la ciència moderna. No portem aquí els seus treballs profunds. N'hi ha prou amb saber que, segons les últimes teories, la intuïció és el coneixement que es genera a través de vies no racionals. Per tant, aquest tipus de coneixement no podem ni explicar ni parlar [1]. Dóna importància a aquest concepte, que tornarà a aparèixer.
Al llarg d'aquest article veurem si la intuïció és una característica exclusiva dels éssers humans. Per a això, primer analitzarem i entendrem les màquines que juguen als escacs. A continuació veurem un dels grans assoliments científics de 2016 per a la revista Science [2]: AlphaGo, la intel·ligència artificial que ha conquistat el joc xinès.
Escacs i màquina Deep Blue

En la cultura occidental, els escacs ha estat la culminació dels jocs estratègics de taula. Intentem analitzar aquest joc a través dels números. En els escacs cada jugador té al principi 16 peces de 6 tipus. Les peces de cada tipus es poden moure de diferents formes. Per tant, en qualsevol situació del joc, un jugador pot realitzar 35 moviments diferents.
Els escacs i aquest tipus de jocs poden aparèixer utilitzant estructures tipus arbre. En l'arrel de l'arbre s'indica l'estat inicial del partit, estant cada peça en la seva posició inicial. Suposem que des de la situació inicial movem un peó. Aquesta nova situació estaria en la primera línia del nostre arbre, amb tots els moviments possibles de totes les altres peces. De cada nova situació sortiran tantes noves branques com moviments possibles i així fins a arribar al final (Figura 1).
Es considera que el nombre de jocs que es poden crear en els escacs, és a dir, el nombre de nodes de l'arbre, és aproximadament 10120. Per a veure amb més claredat la magnitud d'aquest número, imagina't que, segons els millors càlculs, en el nostre univers hi ha 1080 àtoms!
La màquina que per primera vegada va poder vèncer a un gran mestre d'escacs va ser Deep Blue en 1997 [3]. Aquest supercomputador programat per IBM utilitzava l'arbre dels escacs per a prendre decisions. Al no poder conservar tot l'arbre, a partir del node que representava un estat de joc, la màquina analitzava les següents sis línies de profunditat. Avaluava els nodes que hi havia en aquestes profunditats, veient quin era el node pitjor per a ell i quin el millor. Després d'aquesta avaluació, prenia el moviment necessari per a evitar el pitjor node.
La clau d'aquesta estratègia de joc és la capacitat d'avaluació dels nodes. Per a això, IBM va treballar amb grans jugadors d'escacs per a obtenir criteris programables amb el seu coneixement. Aquests criteris es denominen heurístics. IBM va fer una gran feina per a definir i programar aquests heurístics i va acabar derrotant al propi Gary Kasparov.
El joc xinès Go
Les regles del joc go són més senzilles que els escacs, però el joc és molt més complex. Es calcula que hi ha 10761 jocs possibles en el cim! Però això no és el pitjor: en els escacs és possible programar heurístics, però és gairebé impossible definir bé els criteris que funcionen correctament i convertir-los en programes. En general, els experts es posen d'acord en si un moviment ha estat bo o dolent, però no poden explicar per què pensen. Sembla que la intuïció és la clau per a jugar. I, per descomptat, encara no sabem parlar de la intuïció, convertir-la en una fórmula matemàtica o escriure-la com un programa.
Per això, la majoria dels experts deien que, fa no molts anys, no vèiem cap màquina que guanyés als millors jugadors del Go en la dècada dels vint. Perquè ho hem vist. Al març de 2016, Deep Mind [4] va guanyar amb la màquina AlphaGo a un dels grans campions del món, el coreà Lee Sedol.
AlphaGo i el poder d'aprenentatge
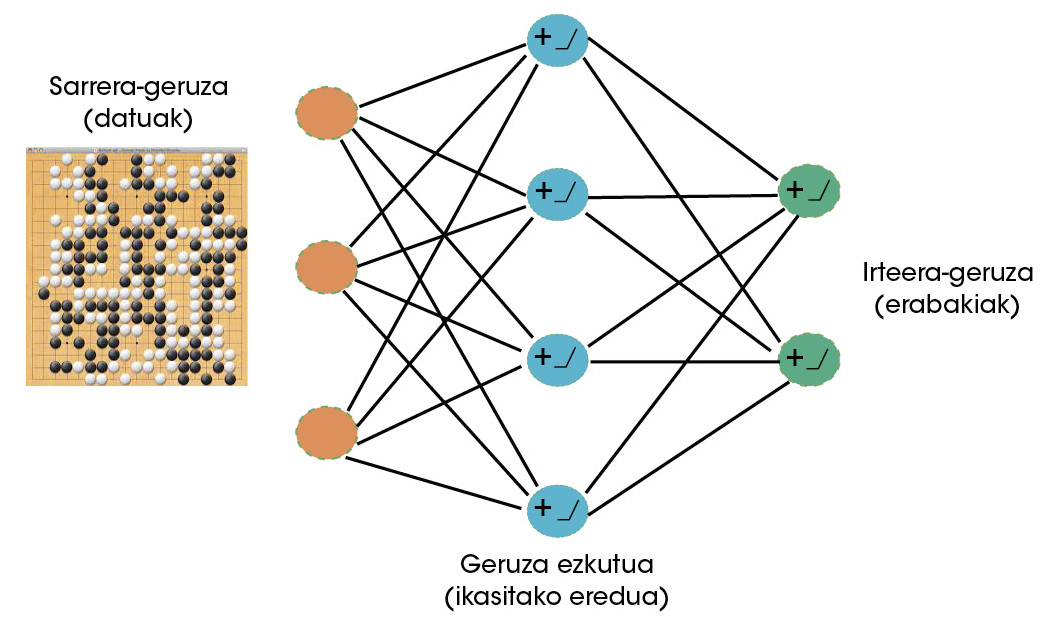
Els científics de Deep Mind van veure clar que el goa podia ser un joc molt apropiat per a màquines amb capacitat d'aprendre. Per tant, les xarxes neuronals van començar a usar-se per a aprendre a jugar en el futur [5]. Les xarxes neuronals són en l'actualitat els algorismes d'aprenentatge més reeixits [6]. Igual que les neurones cerebrals, les neurones artificials reben una sèrie de senyals (dades) que, segons l'après, s'activen o no. Al llarg del procés d'aprenentatge, la xarxa neuronal defineix les dades davant els quals ha d'activar-se i la intensitat d'aquestes activacions. Mitjançant la interconnexió de neurones artificials, la formació de capes, aquestes xarxes poden aprendre comportaments molt complexos (Figura 2).
AlphaGo compta amb dues importants xarxes neuronals: d'una banda tenim una xarxa de polítiques i per un altre una xarxa de valors. L'objectiu de la xarxa de polítiques és endevinar quin serà el següent millor moviment amb una situació de joc. Per a això es combinen dues estratègies d'aprenentatge. Al principi, es van mostrar a la xarxa 30 milions de jugades humanes amb un aprenentatge supervisat. És a dir, per a una situació de joc que veia la xarxa se li ensenyava quin era el següent moviment. Va aprendre a generalitzar d'aquests exemples. Una vegada processats tots els moviments i acabats els estudis, la xarxa política preveia els moviments d'un ésser humà amb una taxa d'invenció del 57%.
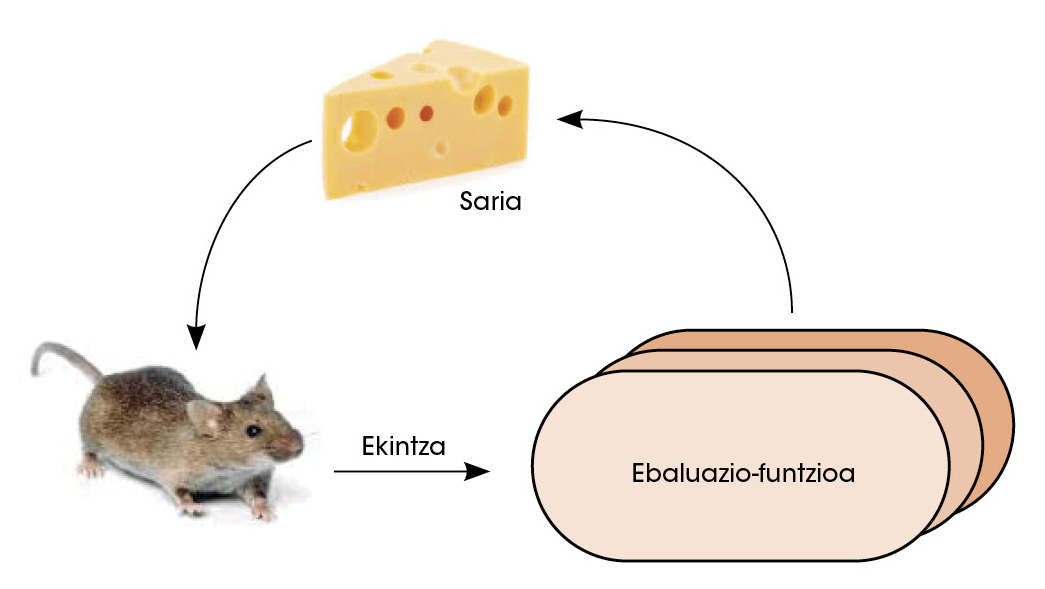
En una segona fase, la xarxa política s'enfronta a si mateixa. Així, amb l'aprenentatge per reforç, la xarxa va millorar la capacitat de decidir quin era el següent millor moviment. En aquesta mena d'estudis es dóna llibertat a la xarxa per a prendre decisions. Si com a conseqüència d'aquestes decisions aconsegueix guanyar, se li atorga el premi. Però si perd se li castiga. Per a maximitzar el nombre de premis, la xarxa aprèn a prendre decisions cada vegada millors (figura 3).
La xarxa de valors té un altre objectiu. La seva missió és valorar la probabilitat de guanyar amb una situació de joc. Per a entrenar aquesta xarxa es van utilitzar milers de partits disputats per AlphaGo contra si mateix. Després de veure tants partits, la xarxa de valors va aprendre a calcular correctament l'oportunitat de guanyar a un jugador davant un escenari de joc.
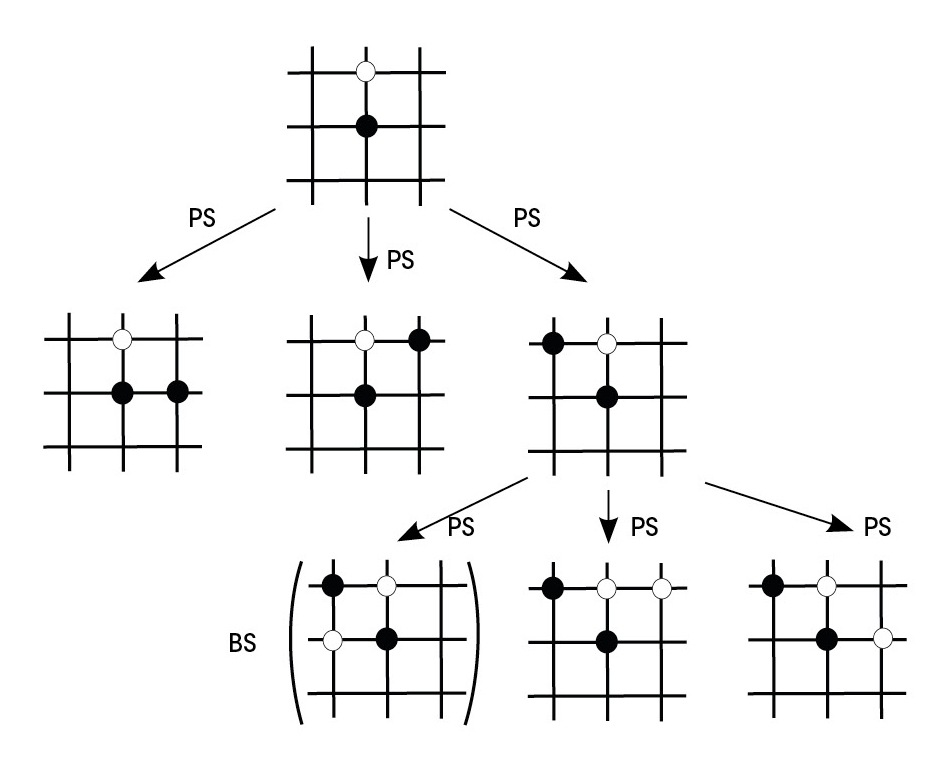
Com es combinen aquestes dues xarxes neuronals per a jugar en l'ull? Per a això hem de tornar a utilitzar l'arbre del joc. AlphaGo, a través d'una situació de joc, utilitza la xarxa política per a predir els pròxims millors moviments. Simula partides per a aquests moviments fins a certa profunditat. Els estats de joc finals d'aquestes partides passen a la xarxa de valors per a calcular la probabilitat de guanyar. D'aquesta manera, AlphaGo manté la branca de joc que més probabilitats li dóna a la xarxa de valors d'entre els moviments que el teixit polític considera millors (figura 4). Cal tenir en compte, a més, que amb més partides, tant la xarxa política com la xarxa de valors es fan millors en el seu treball.
Deep Blue vs AlphaGo
És cert que totes dues màquines prenen decisions mitjançant cerques en l'arbre de joc. Però hi ha una diferència enorme a l'hora d'analitzar-los. En el cas de Deep Blue, els experts van programar manualment els criteris per a avaluar les situacions de joc. Per tant, Deep Blue no podria jugar en un joc que no sigui escacs. I, per descomptat, la seva capacitat de joc serà sempre la mateixa, mentre no hi hagi experts que millorin els heurístics.
AlphaGo utilitza dues xarxes neuronals per a valorar els millors moviments i les situacions de joc. Aquestes xarxes no han estat programades manualment. Ho aconsegueixen aprenent la seva capacitat, per la qual cosa tenen dos avantatges principals:
1 Vàlid per a qualsevol altre joc de taula.
2 A mesura que es juga més, AlphaGo es converteix en millor jugador.
Les maneres de funcionament de totes dues màquines són una excel·lent mostra dels dos grans paradigmes històrics del món de la intel·ligència artificial: Intel·ligència rígida orientada al coneixement de Deep Blue i capacitat d'aprenentatge d'AlphaGoren. Des de la programació manual de les màquines fins a l'abandó del seu propi aprenentatge. Avui dia hem vist bastant clar que la segona idea, la d'aprendre, és molt més poderosa amb exemples com AlphaGo.
Conclusions
La intuïció és un coneixement no racional. Els experts que juguen en Goa recorren a la intuïció per a explicar les seves decisions i anàlisis. Saben com actuar però no són capaços d'explicar-ho correctament. No poden dir per què un moviment és millor que un altre.
AlphaGo ha pogut imitar la funció de la intuïció aprofitant la capacitat d'aprendre. Davant una situació de joc, decideix intuïtivament quin és el següent millor moviment, com ho fa un ésser humà. També decideix intuïtivament si una situació de joc li portarà a guanyar. I sembla que la seva intuïció està per sobre de l'ésser humà.
El gran campió Lee Sedol va utilitzar diverses estratègies per a conquistar AlphaGo. En un partit, intencionadament, es va comportar mal perquè no sabia què fer AlphaGo davant un home que actuava malament. Va fallar. Només va poder guanyar en un partit gràcies a un moviment que pocs esperaven. Segons els enginyers, AlphaGo va preveure aquell moviment, però li va donar una probabilitat molt baixa. Lee Sedol va sorprendre la màquina amb aquest moviment. Però una sola vegada.
El repte de futur és utilitzar les xarxes neuronals i tècniques d'aprenentatge que utilitza AlphaGo per a resoldre els nostres problemes quotidians. Les màquines amb capacitat d'aprenentatge poden ajudar-nos en la indústria, els serveis, la medicina i fins i tot en el propi desenvolupament de la ciència. La intuïció és una de les claus en tots aquests dominis i sembla que ja sabem què fer perquè les màquines aconsegueixin aquesta intuïció.
Bibliografia
[1] Teories de la intuïció: https://es.wikipedia.org/wiki/intuici%C3%B3 (última visita: 28/12/2016)
[2] Science’s top 10 breakthroughs of 2016: http://www.sciencemag.org/news/2016/12/ai-proteinfolding-our-breakthrough-runners? utm_source=sciencemagazine&utm_medium=twitter&utm_campaign=6319issue-10031 (última visita: 28/12/2016).
[3] Deep Blue (chess computer): https://en.wikipedia.org/wiki/deep_blue_(chess_computer) (última visita: 21/01/2017)
[4] Deep Mind: https://deepmind.com/ (última visita: 29/01/2017)
[5] Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
[6] LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." Nature 521.7553 (2015): 436-444.

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia

