

La force de la curiosité
2020/03/01 Azkune Galparsoro, Gorka - Ikertzailea eta irakasleaEuskal Herriko Unibertsitateko Informatika Fakultatea Iturria: Elhuyar aldizkaria
Les expériences et essais réalisés au cours des 15 dernières années sur le fonctionnement du cerveau humain nous conduisent à une conclusion similaire : les cerveaux sont des machines prédictrices de l'avenir. L'un de ceux qui explique le mieux ce courant est le philosophe Andy Clark [1]. Selon lui, la perception humaine n'est qu'une hallucination contrôlée. C'est-à-dire que nous ne percevons pas la réalité telle qu'elle est ; notre cerveau la représente, allume.
Prenons un pelotari. Par exemple, lorsque vous devez brûler un sac, la balle va généralement à 100 km/h. Donc, le pelotari a quelques millisecondes pour décider comment frapper la balle. Ce sont de mauvaises actions parce qu'il faut plus pour obtenir les signaux des yeux au cerveau. Mais le cerveau du pelotari, basé sur l'expérience, peut prédire où sera la balle à tout moment. Votre corps se déplace de cette estimation du cerveau et peut bien frapper la balle.
Andy Clark défend que nos cerveaux se forment dès la naissance pour prédire l'avenir. Ainsi, nous créons des modèles de réalité, des modèles qui comprennent la dynamique du monde. Et nous utilisons ces modèles pour prendre des décisions.
Pour vérifier la validité de ces idées, vous pouvez utiliser, entre autres choses, l'intelligence artificielle. C'est ce que pensaient les chercheurs David Ha et Jürgen Schmidhuber [2].
Modèles de monde et apprentissage par renforcement
L'apprentissage par renforcement est une forme d'apprentissage avec des animaux. Ses bases sont très simples. Par exemple, si nous voulons qu'un chien se sente assis en disant « s'asseoir », nous devons l'enseigner. Ainsi, s’il dit « s’asseoir » et ne fait pas ce que nous voulons, nous le punirons. Mais si vous vous sentez, nous vous donnons un prix. Recevant des récompenses et des punitions, le chien apprend quoi faire quand il entend l'ordre de « s'asseoir ».
Dans le monde de l'intelligence artificielle on utilise aussi l'apprentissage par renfort, parfois avec un grand succès [3]. On peut observer très brièvement dans la figure 1 comment fonctionne un système de renfort.
Mais les solutions de renfort classiques ont deux problèmes principaux:
1. Ils ne servent qu'à une tâche concrète. Ce qui a été appris dans la réalisation d'une tâche n'est pas applicable à une autre, bien qu'il y ait de grandes similitudes entre les deux tâches.
2. Ils doivent recevoir un renfort presque à tout moment. Dans la plupart des tâches du monde réel, vous ne pouvez pas recevoir le renforcement jusqu'à la fin de la tâche. Par exemple, si nous voulons former une machine pour construire un château avec des cartes, nous ne pouvons pas lui donner de renforts jusqu'à ce que le château soit terminé.
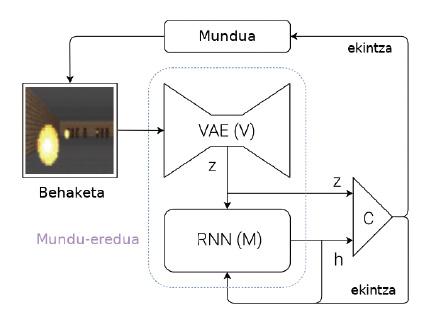
Pour surmonter ces problèmes, Ha et Schmidhuber proposent un système capable d'apprendre des modèles de monde (Figure 2). Expliquons brièvement votre idée : chaque fois qu'une machine reçoit une observation (par exemple, une image avec caméra), elle doit d'abord représenter les informations qu'elle a reçues. Pour cela, ils utilisent des réseaux neuronaux spéciaux, appelés en anglais Variational Auto-Encoders (VAE) (module V de la figure 2). Pensons que ce VAE génère un résumé des caractéristiques les plus importantes qui apparaissent dans une image par caméra (Z de la figure 2, où Z est un vecteur de nombres). Cette observation obtenue à ce moment-là devient l'une des entrées du module M. Le module M est un autre réseau neuronal (dans ce cas, un réseau récursif: RNN). Le module M vise à prédire quelle sera la prochaine observation (Z) qui verra la machine en utilisant la dernière action exécutée et la mémoire (h). Dans le cas du pelotari, le module M dirait où sera la balle dans le futur, en tenant compte des derniers mouvements du pelotari et de la dynamique du monde.
Pour terminer, en partant de l'observation actuelle (Z) et de l'observation attendue pour l'avenir (h), un contrôleur simple (C) est utilisé pour décider quel sera le prochain mouvement de la machine. Le contrôleur, dans ce cas, est un réseau neuronal simple qui apprend par renfort. Mais le modèle mondial (modules V et M) n'est pas entraîné par le renforcement, il n'a donc aucun rapport avec une tâche concrète. En théorie, les êtres humains construisent des modèles de monde indépendamment des tâches que nous voulons accomplir et sont utiles pour toutes les tâches. Quand nous apprenons la dynamique d'une balle, c'est-à-dire quand notre cerveau crée le modèle du mouvement de la balle, nous sommes capables d'utiliser ce modèle dans beaucoup de sports comme la balle, le tennis, le football ou le basket-ball. Les actions à exécuter dans chaque sport sont différentes, car ils ont des normes et des objectifs différents, mais la dynamique du ballon ou de la balle est la même. Ainsi, pour chaque sport, on peut apprendre des contrôleurs par des renforts mais en partageant des modèles de monde.
Comment se forment ces modèles de monde? Simplement en anticipant des observations futures. Dans le cas des réseaux neuronaux, nous donnerions une observation momentanée aux modules V et M et devraient prévoir l'observation du moment suivant. Autrement dit, votre objectif est de minimiser la différence entre ce que vous prédites et ce que vous voyez ci-dessous. Et ils apprennent ainsi à faire de meilleures prédictions. Notez que cet apprentissage n'a rien à voir avec une tâche concrète.
Formulant de la curiosité
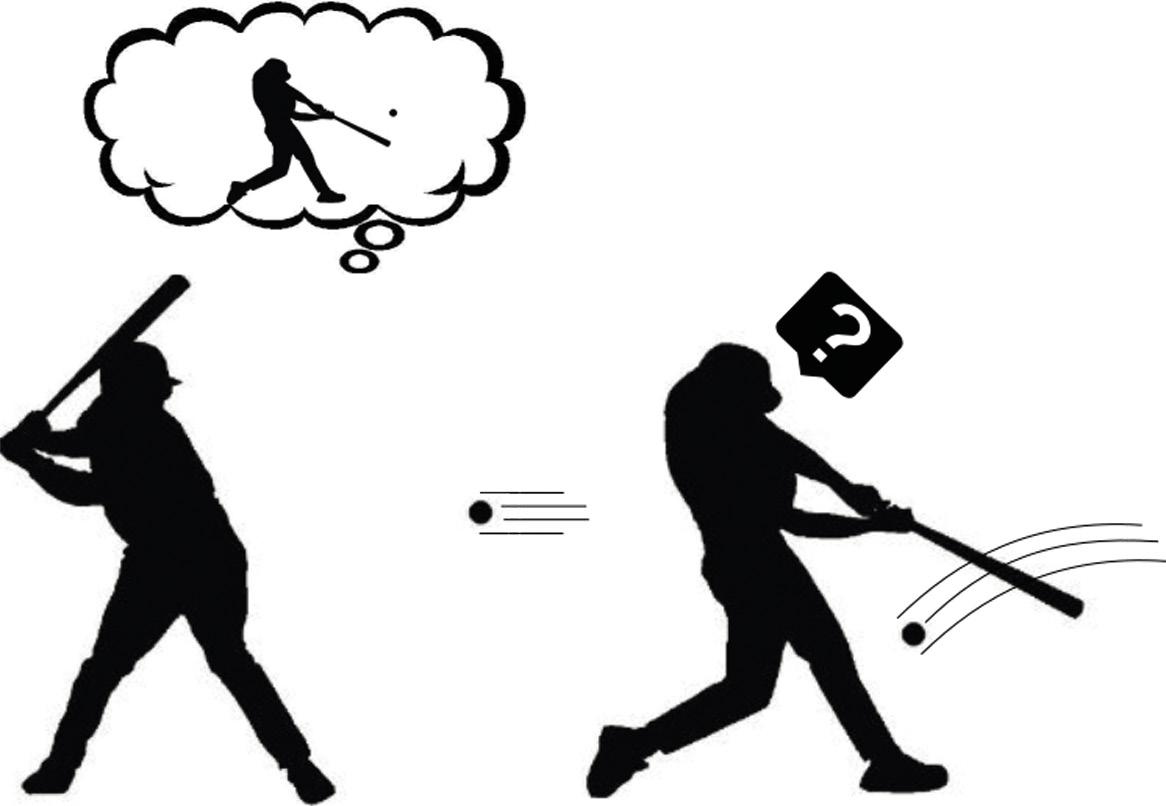
Supposons alors que nous savons déjà comment créer un modèle de monde pour n'importe quelle tâche. Est-ce que cela nous aide à comprendre la curiosité ce modèle de monde capable de prédire l'avenir ? Selon Andy Clark, notre cerveau prédit l'avenir, mais il y a une grande surprise quand ce futur qu'il prédit n'a rien à voir avec ce qu'il observe vraiment. Ces désaccords prouvent que notre modèle de monde n'est pas assez bon. Par conséquent, notre cerveau accorde une attention particulière à ces moments. Il analyse ces étranges observations, exécute diverses actions et cherche le pourquoi de sa surprise (figure 3). N'est-ce pas cette curiosité ? Bingo!
De cette façon, il semble qu'il n'est pas si difficile de formuler la curiosité: comparons la prédiction que génère le modèle mondial avec lequel on l'a réellement vu; s'ils sont semblables, cette situation est connue et donc nous n'avons plus à l'étudier; mais s'ils sont très différents, adaptez notre curiosité. En suivant les idées de l'apprentissage par renfort, la machine ramasse le prix chaque fois qu'elle trouve des situations qu'elle ne peut pas bien prédire pour ses actions. Et ainsi, la machine apprendra à jouer avec son environnement, comme le font les jeunes enfants. Le renfort ainsi formulé est connu comme renfort spontané ou motivation.
Apprentissage guidé par la curiosité
Le centre de recherche OpenAI a voulu analyser la force de la curiosité [4]. Pour cela, ils ont pris beaucoup de jeux vidéo classiques avec lesquels ils ont formé leurs machines. Ces machines étaient basées sur des modèles de monde capables de prédire l'avenir. Et comme nous l'avons dit précédemment, ils formulaient la curiosité. C'est-à-dire, en tenant compte des différences entre ce qui est annoncé et ce qui est effectivement observé.
Ces jeux ont des objectifs différents qui se reflètent dans la fonction de renforcement. Mais ce renforcement a été écarté par les chercheurs d'Openai, en utilisant seulement la curiosité. Par conséquent, les machines recevaient des prix lorsque leurs actions les amenaient à de nouvelles situations, difficiles à prévoir. On peut dire qu'il s'agit de machines formées par pure motivation.
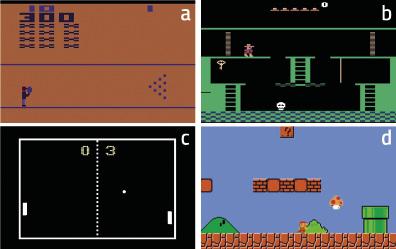
Les résultats ont été étonnants. Par exemple, la machine a appris à surmonter avec curiosité le jeu Bowling (Figure 4.a). Selon les chercheurs, la clé pour expliquer ce résultat est que le score apparaît sur l'écran. Si la machine tire beaucoup de boules, le score change beaucoup. Par conséquent, en principe, ces situations sont les plus difficiles à prévoir, c'est-à-dire celles qui provoquent des changements majeurs dans l'observation. Dans le cas de Pong, figure 4.c, la machine apprend à garder la balle en jouant pendant une longue période, mais pas à gagner. Cependant, il est clair qu'il étudie parfaitement la dynamique du monde. Aussi dans le cas de Super Mario Bros (Figure 4.d) apprend à surmonter le jeu par pure curiosité.
Le plus surprenant, cependant, s’est produit au Montezuma’s Revenge (Figure 4.b). Ce jeu est aujourd'hui très complexe pour les machines, car il nécessite de grandes capacités exploratoires et les renforts sont très rares. Ce jeu est similaire à la salle de scape qui sont tellement à la mode aujourd'hui: vous devez aller compléter les puzzles pour compléter les différentes pièces et surmonter le jeu. Les renforts arrivent quand ils sortent de chaque pièce (s'ils sortent, prix; sinon, punition). Jusqu'à présent, les machines n'ont pas pu se rapprocher des scores humains, car elles ne recevaient pas de renforts en essayant d'explorer les différents objets de chaque classe et de libérer les puzzles. La machine, qui n'a été formée qu'avec curiosité, a eu des résultats similaires aux humains! En définitive, la curiosité pousse la machine à explorer des objets et des recoins rares de chaque classe, et c'est là la clé.
Pour finir
Notre cerveau est très complexe. La perception, la capacité de prédire l'avenir et la curiosité ne sont que quelques éléments du paysage cérébral. Mais ils ont déjà été en mesure de générer d'importants progrès dans le domaine de l'intelligence artificielle. Il semble que derrière ces idées attrayantes, vous pouvez apprécier la trace de la vérité. Par conséquent, nous devrons continuer à étudier pour bien comprendre ces idées qui semblent si puissantes et pouvoir chercher de nouvelles solutions. La mémoire à court et à long terme, l'apprentissage interactif ou l'apprentissage coopératif sont des lignes de recherche déjà ouvertes [5]. Il faut continuer à travailler, parce que la curiosité nous pousse.
Bibliographie Bibliographie
