

Macrocomputers and computer groups
2002/04/01 Roa Zubia, Guillermo - Elhuyar Zientzia Iturria: Elhuyar aldizkaria

What is a macrocomputer? One definition is: "High capacity computer that connects to other computers. Their size depends on memory; the older ones have a main memory of several gigabytes and several terabytes of disk memory." From the current point of view, it is possible that these large machines are defined with another idea: a computer that does things that cannot be done with the home computer. However, both definitions are not very concrete.
The first macrocomputer (if possible) was built in 1975 by the American computer scientist Seymour Cray, who gave it its name: Cray 1. It brings innovative architectural ideas; it was the first vector computer, that is, it had records that worked with vectors (one-dimensional matrices). This idea is very useful for programming it in FORTRAN language, which was the most suitable language for science software, since with matrices calculations were easy. In addition, it had parallel processors.
Companies like Alliant, Ardent or Convex manufactured smaller computers of the same philosophy and many new Cray models have been manufactured. Today, the 'successors' of the Cray 1 computer occupy approximately 10% of the supercomputing market. However, each of these macroodenators has a limited operating capacity, if greater capacity is needed computer equipment must be formed.
Computer groups

Success of interconnected computers. Macrocomputers are very expensive machines and a lot of money is needed for maintenance. However, any company can install, manage and use the network of 'small' computers to perform these gigantic jobs. Therefore, instead of using a computer with more than one processor, the way to work in parallel for many computers of the same processor was worked.
Each computer in a group receives the node name and can have hundreds connected to that network. Equipment can also be connected. The structure that groups 16 groups is called constellation. In view of all this, it is easily understood that a macrocomputer does not have the same computing capacity as several groups. On the other hand, a computer is accessible to a company, both from the point of view of the machine and maintenance, if you connect to networks of other companies the cost is distributed.
Calculation policy
In the 1980s, governments launched many supercomputing centers with macrocomputers. Companies that could not afford this type of machine were given the possibility to connect to these centers. Therefore, governments managed the largest computing needs of companies.

But in those years the smallest computers (personal computers, among others) and the idea of computer groups were developed. The resources needed to form networks were gradually reduced. By the late 1990s companies had lost the trend to supercomputing centers. The groups had important advantages: they managed themselves, the dependence of the government disappeared and, in addition, the computer should not be shared. Consequently, the calculation capacity was higher.
Governments resorted to reducing the number of centers. Currently, in many states there are few of them because they are still necessary for certain tasks (the example is the Blue Gene project). Some centers have become public databases, but the tendency of most research groups is to have private computer equipment. What will be the main future opportunity? In a couple of decades the situation can change.
Blue Gene: application to burn chips
Beyond theoretical computing, it is worth analyzing how the enormous capacity of macrocomputers is applied. The commissioning of these machines is expensive, so take advantage of them, for example, considering that these computers require special air conditioning systems.
What should be calculated on these large machines? The Blue Gene project launched by IBM in 1999 is a good example. This project was launched to investigate one of the most important problems of biochemistry: protein folding. To address this work a computer with a new architecture was devised, whose second objective is to analyze the effectiveness of the new architecture.
Why should we investigate how proteins bend? It's easy, because proteins are responsible for the body's chemical reactions. If proteins "deteriorate" serious diseases occur that often deteriorate due to poor bending. We know that diseases like Alzheimer's, hemophilia, and others have to do with poorly folded proteins.
Forming problem
In general, proteins are amino acid chains. There are 20 types of amino acids from which protein has chemical characteristics according to its sequence. But chemistry is not only determined by the sequence, but the spatial location of amino acids is very important. Amino acids very far from the chain must be physically close in order to perform their function, that is, the chain must be folded in three dimensions properly. If a wrong conformation is taken, the protein cannot work.

But as the protein is synthesized, how do you know its conformation? What pattern does it follow to fold proteins? If we knew, we would invent proteins to produce the desired chemical reaction with the simple definition of the sequence. Blue Gene tries to find these patterns.
Large numbers
Proteins contain hundreds of amino acids. For example, hemoglobin, a protein that carries oxygen in the blood, contains 612 amino acids. The dihedron angle between three consecutive amino acids can have many values, so the protein can contain millions of spatial structures. Only one of them is adequate
Scientists propose patterns of the protein folding process, but the calculus capacity and memory needed to demonstrate that they are or are not correct. The work of a macrocomputer is essential. IBM designed a large computer with a unique architecture: Blue Gene. This project will work on the model of a medium-sized protein containing 300 amino acids.

Quick readers
Blue Gene was designed to be 500 times faster than the fastest computer in the world. How has it been achieved? On many computers, the most time needed to access data from memory chips. The Blue Gene project has designed chips to address this problem.
Each chip consists of two processors: one calculation and one communication. Each chip group handles part of the entire calculation. This strategy greatly accelerates the calculation capacity. In the case of proteins, for example, the working files must be very large (files that remain during calculations), and the duration of the work ultimately depends on the time we search for the data we need.
In complex applications, computers must perform millions of arithmetic operations in the shortest possible time. To do this, about forty years ago, computer scientists invented vector computers. These computers, instead of using simple numbers, use vectors, i.e. lists of numbers (for computer, one-dimensional arrays).
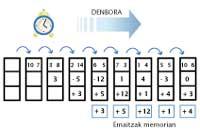
Vector computers use pipe lines for quick calculation. The idea of these pipe-line is very simple, it is the same principle as the production of series. An example is easily understood. Suppose we have to calculate the difference between the data of two lists of numbers, for this we have to follow four steps: a) take a number of each list, b) subtract c) if the result of the subtraction is negative, change the sign and d) store the result in memory. If each step is performed in a microsecond, to treat a couple of numbers four microseconds are needed.
The listings we will use are: 10, 3, 2, 6, 7, 1, 5, 10, … and 7, 8, 14, 5, 3, 4, 5, 6, …
Instead, on a pipe-line, when the first pair of numbers has finished the first step, it goes to the second, but a second pair of numbers enter the first step. Thus, in each microsecond, the interior walls will advance one step and a pair will be incorporated in the first free step. Thus, the operation of the first pair will require three microseconds, but that of the second pair will end in the fourth microsecond (and not in the sixth, as if they were done one by one).
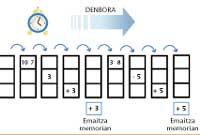
It was a simple example, but it should be noted that computers perform arithmetic operations with mobile comma numbers. (The movable comma script to represent a number uses a mantis and a characteristic, that is, it is a type writing 0.233 x 10 3).
The arithmetic of these numbers requires more steps than integers. Vector macrocomputers incorporate pipe-line calculation systems with mobile comma. In addition, by combining complete vectors with records for the treatment of simple numbers, they can perform extremely fast arithmetic operations. The most famous of the first macrocomputers of this type, Cray 1, dates from 1976.
Many times, a group of small computers can work on a vector computer. That is the main philosophy of computer groups. However, all computers that make up the group must somehow be connected to a network. Each participating computer is called a node. But where is the software that all nodes need? Will they use the joint memory or will each node use yours? From the architectural point of view of the whole system there are three forms of organization. Shared disksThis type of sorting is widely used. The network has general input and output devices, accessible from each node. These devices include files and databases. Thus, the system does not need to share node memories. The main problem of this system is the availability of all nodes. At any given time, all nodes can write or read simultaneously on the general disks. To be able to control all this a synchronization mechanism is necessary: the lock manager. The deterioration of a node in these systems does not affect others. This provides great availability to the system, although sometimes this feature slows down work due to the narrowing generated by the blocking manager activity. Systems without sharingIn these systems there are no disks available for nodes. Therefore, in these systems the number of nodes is not as limited as in previous occasions. These systems have hundreds of nodes. Mirror systemsAlthough data is stored on a general disk on these systems, it is copied to a second to increase availability. Normally this copy is not worked, unless the original disk is damaged. If it gets damaged, this organization recovers data very quickly. These systems normally have only two nodes. Many of the servers that support the Internet network are such systems. |
Twice a year, during the months of June and November, supercomputing congresses are organized to publicize what happened in this area. The last congress, last November, took place in the United States, Denver, and the previous one, in June, in Heilderberg, Germany. These congresses collect data from supercomputing centers and update the Top500 list. This list analyzes the 500 most capacious centers and their characteristics. Changes between the different versions of the list can be found on the following website: http://www.top500.org/ |
As for large calculation centres, in the Basque Country the trend is the same as in the rest of the world. In the past, when macrocomputer operation centres were being promoted, the Basque Government Department of Industry and the Labein technology centre signed an agreement for the installation of a computer centre. It was decided to locate this center in the Zamudio Technology Park.

A Convex macrocomputer was launched that could be used in several companies in the Basque Country. The companies to which it was to be connected belonged mainly to the field of engineering, with the aim of realizing in this gigantic computer the great calculations necessary for the design.
The best configuration of this convex machine was the parallel computer of 8 vector processors. In the beginning, some companies had a great interest. Instead of being a supercomputing center, however, the general trend was to look for other solutions (e.g., self-managed computer groups). For some years it was used by several groups of researchers from the University of the Basque Country, but finally the supercomputing center was suspended.

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia
