

MultiMeteo sait aussi euskera
2001/11/01 Díaz de Ilarraza, Arantza | Sarasola, Kepa | Mayor, Aingeru | Loinaz, Miel | Chevreau, Karine | Coch, José Iturria: Elhuyar aldizkaria

La qualité du travail du traducteur humain sera certainement meilleure et plus riche, mais aujourd'hui, il est possible de créer des documents dans un domaine particulier et technique comme la météorologie, en utilisant des techniques automatiques. Dans
cet article, nous présentons le système interactif Multimeteo qui utilise la création textuelle multilingue dans le domaine de la météorologie, ainsi que l'adaptation que nous avons réalisée à la création en basque. Le système développé offre des prévisions météorologiques quotidiennes à l'adresse suivante : http://www.ingurumena.net/udala //www.inm.es/wwi/Multimeteo/Multimeteo.html
Contexte historique

Bien que la création automatique de texte n'est pas utilisée, il faut mentionner ici un système qui traduit automatiquement les prévisions météorologiques. Le système METEO créé par le groupe TAUM de Montréal a été le système de traduction le plus réussi de tous les temps. Il était difficile de trouver des traducteurs pour des traductions ennuyeuses qui ressemblaient quotidiennement, et le service météorologique officiel du Canada a commencé à rechercher des voies automatiques. Le système METEO obtenu traduit des bulletins météorologiques de l'anglais au français depuis 1977, et 80% de sa traduction est totalement directe. Cependant, le succès de la météorologie n'a pas été étendu, car bien que le système ait été adapté à d'autres questions, aucun résultat de qualité égale n'a été obtenu. Il semble que le domaine des prévisions météorologiques a une adaptation particulière à ce type de processus automatiques.
L'environnement de travail Forecast Generator (FoG) a également été lancé au Canada en 1993. Dans ce système, le météorologue utilise un éditeur graphique pour adapter la carte montrant les données météorologiques, puis le système génère automatiquement la prédiction météorologique en anglais et en français pour la région.
Historique du système multiMeteo
HGMTN tWWiWpWeWtToTopToeVvpVeVtTeDT eHDFFtHNEn 1995, le Service météorologique français (Meteo France) a lancé le projet MultiMeteo pour la publication des prévisions météorologiques en plusieurs langues. Pour cela, il a contacté l'Institut national de météorologie (INM) d'Espagne, le Royal Meteological Institute (RMI) de Belgique, le Zentralanstallt für Meteologie und Geodynamik d'Autriche (ZAMG) et deux entreprises spécialisées dans la création linguistique: Lexiquest, basée à Paris, et CL Services linguistiques de Madrid. Le service de météorologie allemand (DWD) a également été initialement rejoint, mais a ensuite été abandonné.
Ces associations ont présenté le projet « Multilingual Production of Weather Forecasts » et ont obtenu un financement communautaire. Le système a été développé en quatre langues: français, anglais, espagnol et allemand. Les résultats de l'évaluation réalisée en février 1999 ont été très positifs.
En 2000, INM et Lexiquest ont conclu un accord pour étendre le système en quatre langues : le néerlandais, le catalan, le galicien et l'euskera. Le Groupe Ixa et le Centre de terminologie UZEI de la Faculté d'Informatique de San Sebastián nous ont chargés de la diffusion en basque, et en ce moment nous sommes sur le point de terminer la phase de développement du projet.
Procédure habituelle de création de prévisions météorologiques

Deux sources sont utilisées pour la collecte des données météorologiques : la collecte superficielle des données et la collecte spatiale. Les données superficielles sont prises dans les observatoires météorologiques, où sont mesurées et collectées à tout moment les variables physiques qui décrivent l'état de l'atmosphère. Les autres données obtenues de l'espace sont les satellites météorologiques, les satellites géostationnaires METEOSAT et les satellites polaires de la série TIROS-NOAA, qui ne sont pas destinés à envoyer des informations.
Toutes les données numériques obtenues sont traitées par des modèles mathématiques complexes. Les processus automatiques simulent l'évolution des variables physiques dans les prochains jours, générant des matrices de données pour des prévisions météorologiques. Le météorologue a alors la possibilité de retoucher ces matrices de données, c'est-à-dire de compléter et arrondir la prévision avec son expérience. En conclusion, comme indiqué dans le tableau 1, les tableaux présentent des données de température (Te), direction du vent (DD) et force (FF), nuages, pluie, etc. pour différentes heures (périodes de 3 heures dans le cas du système INM). Pour chaque point de la carte, vous obtenez une matrice de ce type.
Avec ces données, les météorologues créent les prévisions météorologiques manuellement. Ce travail est très long et coûteux, surtout quand d'une seule prédiction il faut faire plusieurs versions en différentes langues ou styles (prédictions générales, de plages, de mer, de montagne, par communauté, par province...).
Voici l'intérêt de MultiMeteo. Il ne s'agit pas de remplacer l'œuvre des météorologues, mais de contribuer de manière interactive à leurs tâches, afin que les prédictions puissent être diffusées dans différentes langues et styles. En outre, il permet d'effectuer des prédictions pour différents endroits de la carte.
Un outil de support : création multilingue interactive

Cette technique, en premier lieu, par la création automatique, génère un brouillon à partir de données d'entrée peut-être incomplètes. Bien qu'il ait la capacité de créer du texte en plusieurs langues, le météorologue, pour agir comme correcteur, est offert uniquement dans sa langue maternelle. Si le météorologue souhaite effectuer une correction dans un fragment de texte, il doit cliquer sur la partie à modifier. Ensuite, le menu “pop-up” vous proposera un certain nombre d'options et de modificateurs alternatifs, en choisissant l'un d'eux pour effectuer la correction confortablement. Compte tenu des modifications apportées, le système générera des textes prédictifs dans toutes les langues.
Les avantages de cette technique sont la rapidité (pour produire chaque texte dans chaque langue il faut environ 2 secondes; un traducteur humain a besoin d'environ 10 minutes); la viabilité de la création, même si quelques données n'ont pas encore été recueillies, la haute qualité des textes créés (parfois avec des touches humaines); la facilité d'entretien et d'adaptation; et enfin, l'acceptation de la part des utilisateurs humains (les météorologues ne leur enlèverront pas le poste de travail étranger, mais de langues étrangères).
Création automatique de bulletins d'information
MultiMeteo réalise la création de deux formes:
- Pour la rédaction du titre de chaque paragraphe, un texte fixe est utilisé avec le nom des provinces, et pour écrire l'en-tête des bulletins d'information (voir figure 1), un modèle avec plusieurs variables internes est utilisé, par exemple:
Météo *IS *CO. *MO *FD.
Heure Locale: *FP.
Valeur de l'annonce: *TT.
où:
- La valeur d'IS peut être "par provinces", "par îles" ou rien.
- Valeur du CO - nom des communautés (par exemple pour la "Communauté autonome de Galice").
- Mois MO ("Juin")
- Date de la DF, exprimée en chiffres.
- FP indique l'heure
- Période de prédiction par TT (par exemple, “aujourd'hui de 06:00 à 12:00 de minuit”).
- Pour écrire le corps des paragraphes, une méthode beaucoup plus complexe est utilisée. Les points suivants expliquent l'architecture et les modules nécessaires pour aborder la création automatique à ce niveau.
Architecture générale du système

Le moteur de génération utilisé par le système a été développé en 1994 en français pour la génération automatique de cartes commerciales. En 1995, il s'est étendu à l'anglais en s'intégrant dans un prototype de traduction de manuels techniques. La même année, elle a également intégré le projet « Multilingual Production of Weather Forecasts » pour intégrer de nouveaux langages et fonctionnalités dans la création de bulletins météorologiques (création interactive et gestion des connaissances stylistiques).
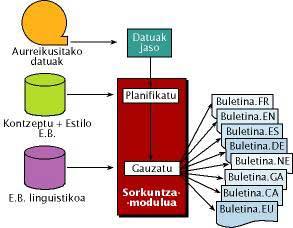
L'architecture du système peut être vu dans la figure 2. La première phase consiste à obtenir et reformater une base de données météorologique permettant l'utilisation de modules de génération. La tâche du module de création est ensuite divisée en deux parties : planifier et exécuter.
Module de planification
La planification utilise des bases de connaissances de concepts et de styles (UE) et est divisée en deux phases:
- Planification générale: le bulletin est organisé en plusieurs paragraphes (en-tête, paragraphe pour chaque province, etc.)
- Planification météorologique: à partir des données d'entrée, le contenu de chaque paragraphe est déterminé. Les événements ( event ) qui doivent apparaître dans le paragraphe et les relations entre eux sont répertoriés en utilisant un interlingua, de sorte que la description soit indépendante des langues. Les modules suivants seront effectués pour chaque langue.
L'événement est un objet conceptuel associé à la situation météorologique ou l'évolution de la situation. Les phénomènes sont de deux types: atomiques et moléculaires.
L'événement atomique représente un paramètre météorologique sans évolution, avec une seule valeur associée (attribut Value). Par exemple, l'événement atomique représentant le ciel couvert est:
Event_CloudCovering4: Event{} Value=Class
CloudCovering_code4; Time_Representation=
TimeRepresentationMod{};}
Class CloudCovering_code4 est un ensemble de concepts simples: Overcast, NoSun et VeryCloudy-Overcast. Chacun de ces concepts est associé à un terme dans chaque langue.
L'événement moléculaire indique plus d'un paramètre. Par exemple, quand on parle de vent, on peut avoir la force, la direction et les données d'évolution. Ils peuvent prendre plusieurs valeurs (Value0, Value1, etc.) attributs), ainsi qu'un opérateur (attribut Operator) qui spécifie la façon de collecter ces valeurs. Par exemple, l'événement moléculaire pour décrire le ciel sans nuages à être couvert est:
GrowingCloudier_Min0: Event_mol{ Value0=Event_CloudCovering0; Value1=
Event_CloudCovering4;
Operator= Class
GrowingCloudier_Min0; Time_Representation=
TimeRepresentationMod{};}
Cet événement moléculaire se manifeste par deux épisodes atomiques et un opérateur. Il sert à situer les événements time - representation dans le temps (présent, passé ou futur) et indique la période (jour, matin, soir, nuit...).
Un concept est choisi à la sortie du module de planification pour chaque événement atomique et pour chaque classe d'attribut Operator des événements moléculaires. En outre, d'autres attributs peuvent être ajoutés (automatiquement ou en interaction avec le météorologue) : indice de probabilité, phase, période...
Module d'exécution
simple
sémantique ( Rsem )
UsemR1_HIVER= Staline1Sem Usem
= Staline 1Sem
Le module pour matérialiser linguistiquement les concepts obtenus dans chaque langue est basé sur la Théorie du Sens - Texte (Mel’cuk 1988, Polguère 1988). Dans cette phase on utilise une base de connaissance linguistique qui est divisée en cinq étapes: prédénotation, sémantique, syntaxe profonde, syntaxe superficielle et morphologie.
- Préindication. À ce stade, un terme correspondant à cette langue est choisi pour chaque concept simple dérivé de la planification. Par exemple, pour le concept simple Overcast du groupe Class CloudCovering_code4 mentionné ci-dessus, un des termes Ciel, Couvert ou Couvert sera sélectionné. Ces termes sont divisés en unités sémantiques ( USem ), avec lesquelles l'expression sémantique ( RS ) est créée (voir ).
- Sémantique. De l'expression sémantique Rsem se forme le graphe de la syntaxe profonde formée par des nœuds et des relations, pour lequel on sélectionne l'unité lexicale correspondant à chaque unité sémantique.
- Syntaxe profonde. Il construit un graphe qui a tous les mots de la phrase à créer dans les nœuds.
- Syntaxe cutanée. Les nœuds sont triés pour déterminer la place à occuper chaque mot dans la phrase.
- Morphologie. La forme de mot qui lui correspond selon l'information morphosyntaxique de chaque noeud est recueillie du dictionnaire. Toutes les formes déclinées sont stockées dans le dictionnaire pour éviter la création morphologique.
Adaptation au basque
diurne
•
•
Le travail informatique pour la diffusion du système MultiMeteo en basque a été développé par le groupe IXA et le travail terminologique a été réalisé par UZEI. Les adaptations au galicien et catalan ont été faites à partir de la version castillane, et ont dû travailler sur tout le lexique, car il n'y avait pas de grands changements dans la syntaxe et la morphologie. Pour l'euskara, même si nous sommes partis de l'espagnol (et parfois du français), la plupart des structures des phrases ont été modifiées et nous avons dû travailler spécialement avec des marques de déclin morphologique.
Nous commençons notre travail en trois phases:
- Collecte et analyse du corpus du temps en basque,
- Connaissance du système multiMeteo et de son architecture, et
- adaptation du système.
L'adaptation a été réalisée en trois sous-phases: nous avons d'abord abordé les événements atomiques (par exemple le «ciel couvert»), puis les événements moléculaires qui étaient faciles (par exemple le «vent, faible, du nord»), et enfin les événements moléculaires qui présentaient des difficultés particulières (par exemple, le ciel, initialement couvert, avec de la pluie, par la suite très couvert temporairement).

Dans chacune des phases d'adaptation, une analyse linguistique préalable, une analyse et une conception de l'information à inclure dans la base de connaissances, une introduction et une preuve de l'information d'un exemple représentatif pour chaque événement et, enfin, une introduction et une preuve de toutes les possibilités pour chaque type d'événement.
Les principales caractéristiques de cette adaptation sont:
- Considérant que les prédictions générées par le système devaient suivre le style télégraphique de l'INM, nous avons décidé d'éliminer les verbes. De même, les modificateurs du nom qui est la zone de la phrase seront séparés par des virgules comme syntagme d'attributs. Par exemple, au lieu de donner “Vent du Nord faible” ou “Vent du Nord et Faible”, le système générera “Vent du Nord, faible”.
- Les évolutions météorologiques exprimées en français et en espagnol par gerundio se réalisent autrement en basque. Par exemple, "Ciel clair à la hausse à nuageux" nous allons créer en basque comme suit: « Le ciel, au début, est sombre, puis nuageux ».
- Dans le dictionnaire, nous avons écrit toutes les formes de mots (parfois des unités multi-mots) qui peuvent être utilisés dans les bulletins. Dans les bulletins sont employés par moments deux cas : absolu et sociatif. La devise du mot est également possible.
Si par la suite le système devait être étendu avec d'autres styles, plus de cas de déclin devraient être utilisés, il faudrait donc introduire ces cas dans le dictionnaire. Voyons, par exemple, l'introduction du vocabulaire du mot pluie:
BA_Euri1 :LexemeNomBA{
CatMorph = NOM; SsCatMorph = COMMUN; UMorph=
[ morpho{Cas= ABS;
Nom= SINGULIER;UMG= "euria"},
morpho}=
Phuns;
- La zone de la phrase, par défaut, aura le cas du déclin absolu, et le cas des modificateurs de la zone sera déterminé dans la définition du concept ou terme. Par exemple, le concept qui crée "Le ciel, couvert, avec la pluie" doit préciser que le terme couvrir occupera l'absolutif singulier et la pluie sociative singulière. Dans l'absolutif singulier apparaît le terme zeru parce que c'est l'espace de la prière.
- En euskera, le cas de déclin du syntagme adhère au dernier mot de chaque syntagme, et le système ne donne pas l'occasion de le gérer de manière élégante. Pour cela, nous avons dû ajouter une série de règles: d'une part, au niveau conceptuel, le système colle la marque de cas à tous les mots de chaque syntagme, puis quand les mots sont ordonnés dans la phase de syntaxe superficielle, il enlève le cas à ceux qui ne sont pas le dernier mot. Par exemple, pour créer la phrase «Le ciel, couvert, avec des pluies générales et des tempêtes», on indique dans un concept que tout le syntagme de pluie générale et des tempêtes doit porter le cas du sociatif; pour cela il faut marquer tous les termes avec le cas pluie (soz)+general(soz)+ekaitz(soz) ; pour que plus tard les termes pluie, et général se démarquent».
Dans le tableau 3 on peut observer comment se sont matérialisés plusieurs concepts atomiques en basque (on inclut la réalisation en espagnol et français de référence).
Le tableau 4 montre l'exécution de plusieurs concepts moléculaires. Les variables indiquent, quand elles sont indiquées, les valeurs de cet événement : Variables N état des nuages (oscarbia, sous nuage, couvert...); Variables DD direction du vent (nord, sud-ouest, etc.) ); Les variables FF sont la force du vent (modérée, forte,...); Variables TS précipitations (pluie, sirimiri...), Période PER (matins...)...
Œuvres d'avenir
tempêtes de grêle
Réduire à N2
Augmentation/ Diminution N2
tempêtes à N2
FF2 Avancez
passager FF2
Le projet est actuellement dans les dernières phases de développement. La prochaine étape est un test massif pour analyser les erreurs possibles dans le système. Ensuite, effectuer les changements nécessaires et l'évaluation finale. Cependant, l'adaptation effectuée est déjà intégrée dans le système de l'INM et chaque jour les prévisions météorologiques des communautés de l'État espagnol sont offertes sur le web http://www.inm.es/wwi/ MultiMeteo/Multimeteo.html.
Outre l'écriture télégraphique de l'objectif général, la réalisation de prédictions à but spécial (pour les plages, les montagnards, les skieurs...) et l'élaboration d'écritures plus riches (par exemple, l'introduction de verbes à phrases complètes) seraient des étapes réalisables à moyen terme. Ce type de versions complètes ont été faites en français et sont actuellement utilisés. Pour l'instant il suffirait d'analyser l'utilité du système développé pour l'euskera, et si la nécessité était détectée par la suite, alors il faudrait aborder l'organisation des améliorations mentionnées.
