

Comment préparez-vous le café?
2017/03/01 Azkune Galparsoro, Gorka - Ikertzailea eta irakasleaEuskal Herriko Unibertsitateko Informatika Fakultatea Iturria: Elhuyar aldizkaria

Dans notre quotidien, nous faisons beaucoup de choses: sortir du lit, prendre le petit déjeuner, regarder la télévision, etc. La capacité de réalisation de chacune de ces activités est fondamentale pour une bonne qualité de vie. Et c'est précisément le but des foyers intelligents : apporter le soutien nécessaire aux personnes qui y vivent pour pouvoir mener leurs activités quotidiennes.
Mais que sont les maisons intelligentes ? À la base sont des maisons normales, où des capteurs et des ordinateurs sont placés. Les capteurs fournissent des informations sur les activités des personnes et des ordinateurs traitent ces informations pour comprendre les comportements et prendre des décisions. Dans cet article, nous analyserons la première partie, collectons les informations des capteurs et détectons les activités humaines.
Pour commencer, nous avons besoin de capteurs. Il existe de nombreux types de capteurs sur le marché et il ne nous serait pas possible de les expliquer. Pour ce travail, pensons que les capteurs sont collés dans nos objets et outils quotidiens. Ainsi, par exemple, lorsque vous prenez un verre, le capteur s'allume et enregistre cette action. Recueillir des informations de ce type dans le temps, l'ordinateur doit connaître les activités. Par exemple, si une personne prend une tasse, met la cafetière en marche, puis attrape le sucre, l'ordinateur devrait savoir que cette personne prépare un café.
Comment détecter les activités humaines ?
Si vous regardez la recherche effectuée à ce jour, vous pouvez trouver deux courants principaux pour la détection des activités humaines:
- Techniques basées sur des données: prise de données sensorielles recueillies par une personne, application d'apprentissage automatique et apprentissage des activités humaines. L'ordinateur apprend des données brutes. Ces techniques ont de nombreux aspects positifs, comme ils sont capables d'apprendre des pratiques personnalisées, qui apprennent des données de chaque personne, et s'adaptent aux changements des personnes. Mais il y a aussi des inconvénients : des difficultés pour généraliser ce qu'on a appris – on ne peut pas utiliser ce qu'on a appris d'une personne à une autre – et qu'en phase d'apprentissage on a besoin de nombreuses données étiquetées, par exemple. Ce dernier est un problème majeur car il est très difficile d'obtenir des données étiquetées.
- Techniques basées sur la connaissance : la connaissance que nous avons de chaque activité est codifiée dans des modèles logiques, puis on observe si l'information des capteurs est cohérente avec ces modèles pour trouver une activité adéquate. Avantages : les modèles définis s'appliquent à n'importe qui, sans besoin de données pour le démarrage du système (pas de phase d'apprentissage). Inconvénients: obtenir des modèles personnalisés est très difficile, car il est difficile de connaître à l'avance tous les détails de chaque personne. D'autre part, les modèles d'action sont rigides et ne peuvent pas s'adapter aux changements que subissent les gens au fil du temps.
En approfondissant les avantages et les inconvénients des deux courants, on voit assez clairement qu'ils présentent des caractéristiques opposées. Ce que font bien les techniques basées sur des données, les techniques basées sur la connaissance ne peuvent pas bien faire, et vice versa. Il s'agit de deux approches différentes pour résoudre un même problème, qui sont contradictoires, mais sont-ils incompatibles?
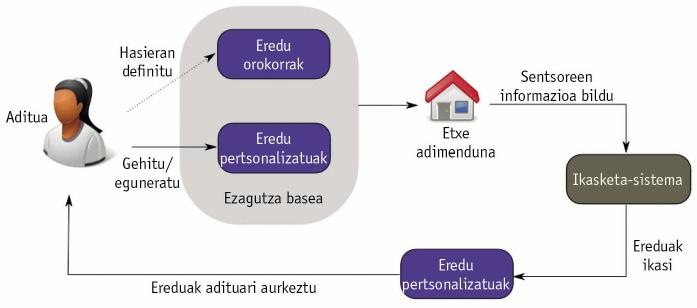
À la recherche de techniques hybrides
Il serait bon que les deux courants se réunissent en quelque sorte et fusionnent le meilleur des deux mondes, non ? C'est ce qui a été fait dans cette thèse. Un nouveau processus de modélisation de l'activité humaine a été proposé, développé et testé. La figure 2 montre le diagramme de ce nouveau processus. La proposition combine des techniques basées sur la connaissance et les données, offrant une solution hybride. Tout d'abord, un expert définit des modèles généraux de performance applicables à toute personne. Voici les informations sensorielles générées par une personne vivant dans une maison intelligente. En utilisant des modèles généraux et un algorithme d'apprentissage basé sur des données, les modèles initiaux sont enrichis en apprenant les détails de cette personne concrète. On apprend ainsi des modèles personnalisés. Ces modèles sont présentés à l'expert pour les incorporer à la base de connaissances.
De cette façon, un système a été créé qui unit les meilleures caractéristiques des deux courants. D'une part, la connaissance humaine est utilisée pour créer des modèles généraux. Ces modèles généraux recueillent les caractéristiques générales d'une activité, de sorte qu'ils sont applicables à toute personne. D'autre part, il est capable d'apprendre des modèles personnalisés, recueillant des informations sensorielles d'une personne et appliquant des algorithmes basés sur des données. En outre, l'utilisation de modèles généraux dans cet apprentissage évite le besoin de données étiquetées, dépassant ainsi un aspect négatif des techniques basées sur des données. Ainsi, comme le comportement d'une personne change, les modèles personnalisés qui sont apprises sont adaptés.
Avec un meilleur exemple
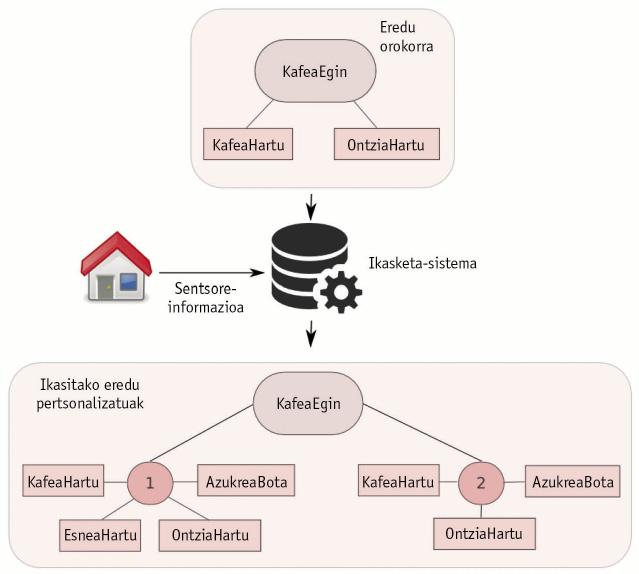
Essayons de mieux comprendre la proposition présentée à la figure 2 avec un exemple simple. Prenons l'activité de faire du café. Comme nous le savons tous, pour faire du café, vous devez prendre du café et avoir un seau à boire. Par conséquent, l'activité de café aura deux actions obligatoires: prendre le café et prendre l'emballage. Comme on le voit, une activité est divisée en actions. Nous venons de définir un modèle général en composant deux actions. Ce modèle est applicable à toute personne, car personne dans le monde est capable de faire un café sans café ni verres (Figure 3).
Maintenant, supposons que la personne qui vit dans la maison intelligente cuisine habituellement le café de deux façons: parfois il prépare du café avec du lait, du café, du lait, du récipient et du sucre; parfois il prépare du café seul avec du café, du récipient et du sucre. Le processus proposé dans la thèse étudie ces modèles personnalisés à partir de modèles généraux et de données de capteurs. Il faut insister pour que ces données de capteurs ne soient pas étiquetées, dépassant ainsi la faiblesse des techniques basées sur les données les plus utilisées.
Algorithme d'apprentissage de modèles personnalisés
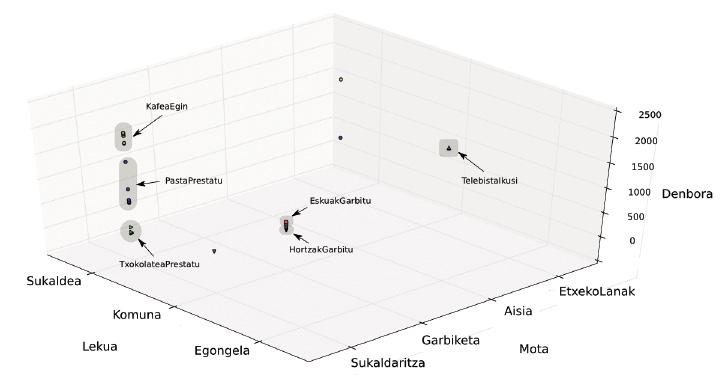
Cet article ne décrit pas avec précision l'algorithme d'apprentissage développé dans la thèse, mais essayons d'expliquer les idées principales (Figure 4). Les actions d'une personne peuvent être encadrées sur trois axes:
- Lieu où la personne a fait l'action: cuisine, salle de bain...
- Objet de l'action réalisée (type): nettoyage, cuisine, loisirs...
- Moment (jour et heure) où l'action a eu lieu.
Ces actions sont perçues par des capteurs. Par conséquent, si, comme une personne effectue ses activités quotidiennes, nous dessinons sur ces trois axes les actions détectées, nous nous rendons compte que les activités peuvent être décrites en recueillant des actions proches les unes des autres.
Par conséquent, l'algorithme d'apprentissage développé dans la thèse:
Regroupez des actions proches de l'espace d'activités en différents groupes (on l'appelle cluster).
À partir de modèles généraux, chacun de ces groupes invente l'activité à laquelle il appartient. Pour ce faire, on observe si les modèles généraux sont cohérents avec ces groupes d'action.
Il couvre tous les groupes d'action pour une activité et trouve des évolutions communes, apprenant des modèles personnalisés.
De cette façon, on apprend des modèles d'action spécifiques pour chaque personne, apprenant toutes les actions réalisées par chaque personne. De plus, si ce processus d'apprentissage se répète au fil du temps, au fur et à mesure que de nouvelles données sont collectées, on peut détecter les évolutions qu'une personne peut expérimenter à cette époque et apprendre correctement l'évolution de cette personne. Autrement dit, on peut apprendre les changements qu'une personne peut avoir dans la façon de réaliser les mêmes activités, en apprenant des actions concrètes.
Conclusions
Pourquoi les modèles personnalisés sont-ils si importants? D'une part, parce qu'ils permettent de fournir à chaque personne l'aide dont il a besoin. Par exemple, si une personne ajoute toujours du sucre au café (modèle personnel) et à un moment donné on voit qu'il n'a pas mis de sucre, on peut le rappeler. La maison intelligente sera mieux adaptée aux personnes qui y vivent.
D'autre part, les modèles personnalisés sont importants pour leur utilisation potentielle dans la santé. Geriatras et neurologues ont montré que les changements dans les activités quotidiennes permettent de prédiagnostiquer des maladies mentales. Les techniques développées dans cette thèse peuvent être une voie pour analyser avec précision ces évolutions et changements. Par conséquent, l'étude d'activités personnalisées au fil du temps peut aider beaucoup à combattre ces maladies, car avant de montrer d'autres symptômes médicaux, nous pouvons commencer à traiter la maladie.
Dans le futur, nous devrons continuer à travailler pour résoudre les problèmes qui restent dans l'air. Comment étendre ce type de solutions à des situations plus réelles ? Est-ce qu'il y a beaucoup de gens qui vivent dans la même maison et font des activités conjointes? Comment éviter de placer un capteur dans chaque recoin et objet de la maison sans renoncer aux détails des activités ?
Il reste encore beaucoup à faire dans les systèmes de détection d'activités humaines, mais nous pensons que cela vaut parce que les avantages qu'ils peuvent rapporter pourraient être importants. Nous pourrions être face à une voie d'amélioration substantielle de la qualité de vie des personnes et nous devons en profiter.
Bibliographie Bibliographie

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia
