

Elhuyar desenvolupa un sistema multilingüe per a extreure el sentiment dels missatges de les xarxes socials
2019/09/27 Galarraga Aiestaran, Ana - Elhuyar Zientzia Iturria: Elhuyar aldizkaria
En les xarxes socials, els usuaris aporten informació sobre entitats, empreses o temes concrets. Els sistemes d'extracció d'informació permeten a les empreses conèixer, per exemple, el prestigi que tenen en la societat; o a les institucions públiques, conèixer l'actitud de la societat davant les seves polítiques.
Ja existien sistemes d'elaboració en diversos idiomes, però no en basc. I la investigadora ha recordat que prop del 15% dels tuits escrits a Euskal Herria són en basc (un total de 2,5-2,8 milions de tuits a l'any). La resta són principalment en castellà i francès, i alguns (en menor mesura) en anglès. Per tant, Sant Vicent ha desenvolupat en aquestes quatre llengües els recursos que conformen el sistema per a analitzar el sentiment dels missatges en les xarxes socials.
“El primer pas va ser crear lèxics de polaritat”, ha explicat Sant Vicent, és a dir, crear llistes de paraules que per si mateixes tenen un sentiment positiu o negatiu: dolent, dolent i bo… “En fer-ho cal tenir en compte el context”, ha advertit l'investigador. De fet, segons el context, una mateixa paraula pot tenir diferent polaritat: “Baixar les vendes és dolent, mentre que baixar l'atur és bo. Per tant, la polaritat dels descensos varia segons el context”. A més cal tenir en compte les negatives (no, però sí…) i la ironia.
L'escriptura informal pròpia de Twitter també genera problemes. “En Twitter molts realitzen una espècie de transcripció del llenguatge oral o barregen dues llengües en un mateix lloc. A vegades, per a donar èmfasi a una paraula, es repeteix l'última vocal i s'utilitzen les emoticones per a expressar sentiments”. A més, existeixen partícules reforzantes i reductores, molt poques… que han estat considerades en l'elaboració del lèxic.
Aprenentatge automàtic
El següent pas ha estat la integració del lèxic en els sistemes d'aprenentatge automàtic. Per a entrenar aquest tipus de sistemes s'han utilitzat milers d'exemples, classificats manualment: positiu, negatiu o neutre. “Amb ells ensenyem al sistema un model matemàtic, de manera que quan vingui un nou exemple, dirà si és positiu, negatiu o neutre sobre la base dels anteriors”.
“Hem aconseguit que la taxa d'invenció de la classificació en basca sigui similar a la d'altres llengües”, ha assenyalat Sant Vicent. En l'actualitat, la taxa d'invenció se situa entorn del 75%, però els membres d'Elhuyar estan treballant per a millorar el resultat basant-se en xarxes neuronals. Així mateix, encara que al principi el sistema només extreia les opinions dels textos, ara és capaç d'analitzar vídeos i àudios i de detectar les opinions presents en ells.
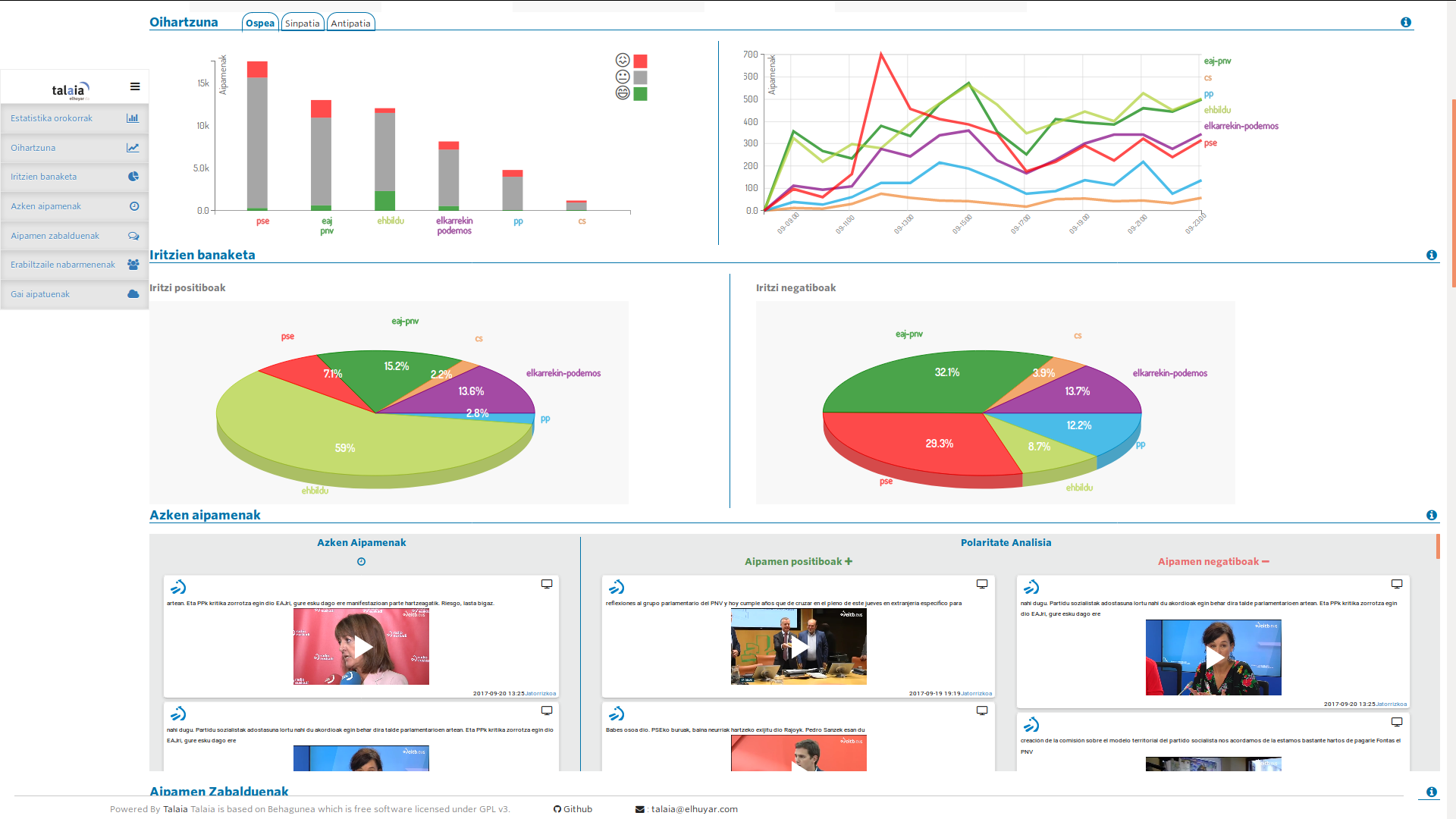
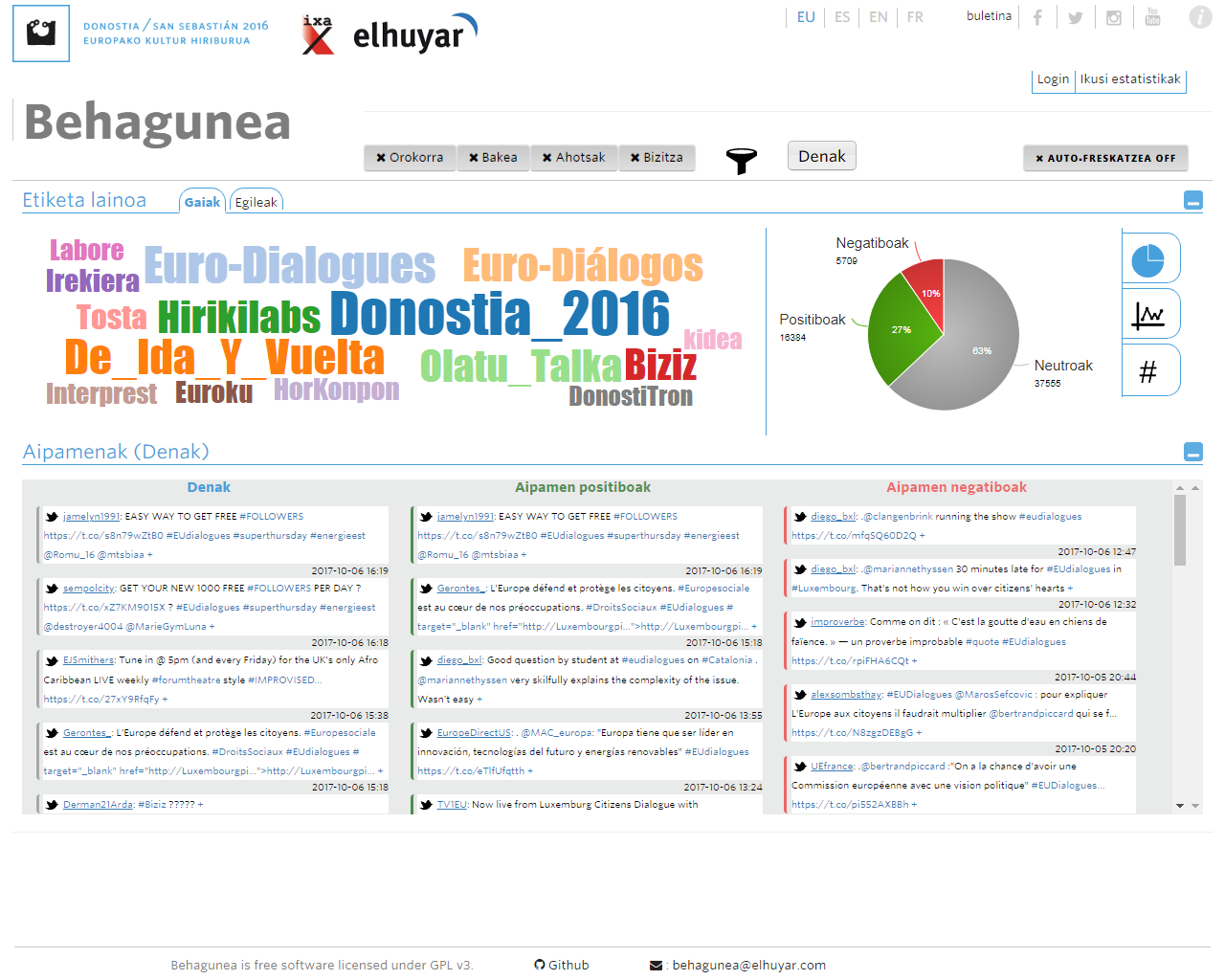
Ja ho han utilitzat en casos reals. Per exemple, a través de Behagunea es va realitzar el seguiment dels projectes de la Capitalitat Donostia 2016. Al costat de la notícia, es va seguir la campanya electoral per al Parlament Basc 2016 i en 2018, amb l'Institut de Criminologia de la UPV, s'ha analitzat l'actitud de les víctimes del terrorisme en les xarxes socials.
El treball de recerca s'ha realitzat en col·laboració amb el grup IXA i tots els resultats estan disponibles en la web d'Elhuyar de Tecnologies Lingüístiques.

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia
