

Golden data
1996/09/01 Waliño, Josu - Elhuyar Fundazioa Iturria: Elhuyar aldizkaria

Currently, the data set that houses any organization is huge. It is true that many of these data are stored useless, but to analyze this large group and extract the relevant information in it, although in small quantities, it is as difficult as looking for a needle between straw. However, the economic benefits that can be reported to a company are very high. With a simple example, you will understand better what we want to transmit, suppose you are the manager of a restaurant and that, based on the different combinations of menus that your customers usually ask, you know what new dish you should offer. The advantages are evident. And the same example serves us to obtain information that supermarkets, bags, large companies or the police themselves can use. And this is only the beginning.
All this is possible today thanks to a new technique called data mining. The scientists who are developing this technique try to take a complete set of data and, through a series of statistical studies, discover possible relationships between the data, excluding the garbage from this data set and collecting really relevant information. They work as gold seekers, abducting the land of rivers, looking for small pieces of gold.
Access to information: obstacle course
To reach these results, different techniques can be used. One of them is the so-called “inducing normative trees”, a method that, through different combinations, will explain the most appropriate standards. For example, “Salad and tortilla of sticks at the time with chuleta peppers”. Although it seems insignificant, this type of combinations with available data sets can become a problem due to the complexity of the combinations that are generated through this procedure: “Potatoes B ALDIN Y (NO fillets and peppers Y (NO ice cream and coffee) Y ...”
To overcome these problems, more advanced techniques have been developed, among which is the use of neuronal networks. The contribution of this system to its operation consists in trying to imitate the logic of human thought to seek the existing relationships between data. Neural networks offer better results than induction (an invention rate close to 75%), but the set of rules used to relate data can be very complex and often incomprehensible. This poses two problems: on the one hand, the impossibility of explaining to clients who have requested an analysis of the data on what the process is based on, as the risk of failure of some companies on which it depends, and on the other, the impossibility of reviewing the basic rules in case of failure in the network.
But these problems will be resolved shortly. Currently, “genetic algorithms” have been used, applying principles based on rules of financial measures when creating data. Although this technique is not very effective, it is more understandable for customers. The other option is to use simple logical methods to find rules that explain the relationships between the data, or based on a normal disjunctive form, which gives very good results.
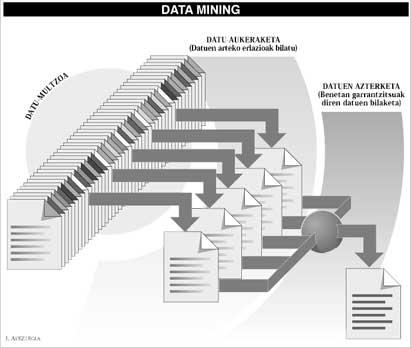
But, without a doubt, among the most successful and promising techniques of today are imposing those based on natural language: techniques that use words common to the language to control the computer. The reason for its success is evident: today, most of the existing data in the world are found in the ordinary text, saved on paper, microchips or pages of the word processor, so its reading is difficult for data search engines.
Thus, the advantages of this new technique are evident, since thanks to them software packages have been created that analyze data in simple texts. Thus, we can understand the interest shown in some sectors to develop these techniques. For example, it is enough to have as text the lists of possible suspects of the police, using the theory and linguistic analysis of the sets that this program uses, to obtain a quick answer directly asking “Who is the greatest suspect?”
This can be surprising, but it will only be the first step of a long process, a newly created technique that will allow us to surprise in different applications that can still have more possibilities.

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia

