

Données dorées
1996/09/01 Waliño, Josu - Elhuyar Fundazioa Iturria: Elhuyar aldizkaria

Actuellement, l'ensemble de données qui héberge n'importe quelle organisation est énorme. Il est vrai que beaucoup de ces données sont stockées inutilement, mais analyser ce grand groupe et extraire les informations pertinentes qui y sont, même si en petites quantités, il est aussi difficile de rechercher une aiguille entre paille. Cependant, les avantages économiques que vous pouvez rapporter à une entreprise sont très élevés. Avec un simple exemple, vous comprendrez mieux ce que nous voulons transmettre, supposons que vous êtes le gestionnaire d'un restaurant et que, sur la base des différentes combinaisons de menus que vos clients demandent souvent, vous savez quel nouveau plat vous convient d'offrir. Les avantages sont évidents. Et le même exemple nous sert à obtenir des informations que les supermarchés, les sacs, les grandes entreprises ou la police elle-même peuvent utiliser. Et ce n'est que le début.
Tout cela est possible aujourd'hui grâce à une nouvelle technique appelée data mining. Les scientifiques qui développent cette technique essaient de prendre un ensemble complet de données et, à travers une série d'études statistiques, de découvrir les relations possibles entre les données, en excluant les déchets de cet ensemble de données et en recueillant des informations réellement pertinentes. Ils travaillent comme chercheurs d'or, en enlevant la terre des rivières, à la recherche de petits morceaux d'or.
Accès à l'information : course aux obstacles
Pour atteindre ces résultats, différentes techniques peuvent être utilisées. L'une d'elles est appelée « induction d'arbres normatifs », une méthode qui, par différentes combinaisons, nous expliquera les normes les plus adéquates. Par exemple, “Salade et omelette de bâtons par heure avec des poivrons de côtelette”. Même si cela semble insignifiant, ce type de combinaisons avec les ensembles de données disponibles peut devenir un problème en raison de la complexité des combinaisons générées par cette procédure: “Pommes de terre B ALDIN Y (pas de filets et poivrons Y (pas de crème glacée et café) Et ...”
Pour surmonter ces problèmes, des techniques plus avancées ont été développées, parmi lesquelles l'utilisation de réseaux neuronaux. La contribution de ce système à son fonctionnement consiste à essayer d'imiter la logique de la pensée humaine pour rechercher les relations existantes entre les données. Les réseaux neuronaux offrent de meilleurs résultats que l'induction (un taux d'invention proche de 75%), mais l'ensemble des règles utilisées pour relier les données peut s'avérer très complexe et souvent incompréhensible. Cela pose deux problèmes: d'une part, l'impossibilité d'expliquer aux clients qui ont demandé une analyse des données sur lesquelles le processus est basé, comme le risque d'échec de certaines entreprises dont il dépend, et d'autre part, l'impossibilité de revoir les règles de base en cas de panne sur le réseau.
Mais ces problèmes seront résolus bientôt. Actuellement, on a commencé à utiliser des «algorithmes génétiques», en appliquant des principes basés sur des normes de mesures financières au moment de créer des données. Bien que cette technique n'est pas très efficace, il est plus compréhensible pour les clients. L'autre option est d'utiliser des méthodes logiques simples pour trouver des règles qui expliquent les relations entre les données, ou basées sur une forme normale disjonctive, qui donne de très bons résultats.
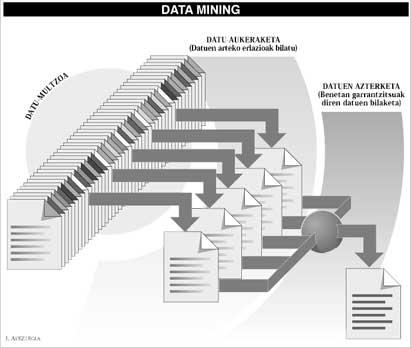
Mais, sans aucun doute, parmi les techniques les plus réussies et prometteuses d'aujourd'hui sont imposées basées sur le langage naturel: techniques qui utilisent des mots communs au langage pour contrôler l'ordinateur. La raison de leur succès est évidente: aujourd'hui, la plupart des données existantes dans le monde se trouvent dans le texte ordinaire, enregistrées sur papier, microcircuits ou pages du traitement de texte, de sorte que leur lecture est difficile pour les moteurs de recherche de données.
Ainsi, les avantages de cette nouvelle technique sont évidents, car grâce à elles ont été créés des logiciels qui analysent des données dans des textes simples. On peut ainsi comprendre l'intérêt manifesté dans certains secteurs pour le développement de ces techniques. Par exemple, il suffit d'avoir comme texte les listes des suspects potentiels de la police, en utilisant la théorie et l'analyse linguistique des ensembles que ce programme utilise, pour obtenir une réponse rapide en demandant directement “Qui est le plus grand suspect?”.
Cela peut être surprenant, mais ce ne sera que la première étape d'un long processus, une technique nouvellement créée qui nous permettra de surprendre dans des applications différentes qui peuvent encore avoir plus de possibilités.

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia

