

Idioma dels números
2018/11/30 Azkune Galparsoro, Gorka - Ikertzailea eta irakasleaEuskal Herriko Unibertsitateko Informatika Fakultatea Iturria: Elhuyar aldizkaria

La intel·ligència humana és molt complexa. Tan complex que encara no hem trencat la seva pell. No obstant això, és clar que un dels pilars d'aquesta intel·ligència és el llenguatge. El llenguatge ens ha permès expressar conceptes complexos, donar forma a les idees i transmetre-les als nostres companys, estructurar cultures riques i deixar petjada en les següents generacions.
Tenint en compte la importància del llenguatge en la nostra ment, s'ha convertit en un tema fonamental de recerca en el camp de la intel·ligència artificial. Ho diem processament de llenguatges naturals (LNP) i molts ho podem veure en més aplicacions de les que pensem: El LNP s'utilitza en traductors automàtics per a identificar els missatges spam i classificar el comentari d'un producte que hem comprat en Amazon.
En els últims anys la revolució de les xarxes neuronals artificials ha arribat també a l'àmbit del LNP, amb espectaculars conclusions pràctiques [1]. Però no sols això: ens ha posat de manifest interessants pistes sobre com es relacionen paraules i números.
Representació de paraules per a màquines
Suposem que som directors de màrqueting d'una empresa d'ulleres. Hem llançat unes ulleres noves i volem recollir les opinions dels compradors. Per a això se'ns ha ocorregut utilitzar la xarxa social Twitter. Crearem l'etiqueta que porta el nom de les nostres noves ulleres per a saber què escriuen els nostres clients sobre les ulleres. El problema és que, com la nostra empresa embeni a tot el món, esperem molts tuits. Així que no pots llegir tots els tuits! Ens agradaria que tot aquest treball el fes l'ordinador.
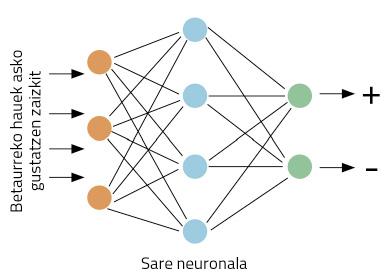
Concretarem millor els treballs: prenent un ocell, el nostre ordinador ha de decidir si es dóna una opinió positiva o negativa sobre les nostres ulleres. Comencem treballant. Aquest tipus de problemes són adequats per a xarxes neuronals. La idea és senzilla: ensenya a la xarxa neuronal diversos tuits, indicant si són positius o negatius; a través de la visualització d'exemples, la xarxa aprendrà a distingir entre positius i negatius (Figura 1).
Però tenim un altre problema: les xarxes neuronals treballen amb números, no amb paraules. Com representem les paraules amb números? En el món del LNP s'ha fet una gran feina sobre aquest tema, la qual cosa fa que hi hagi moltes formes de representació de paraules. La idea més senzilla és la denominada one-hot vector en anglès.
Imaginem quatre paraules: a dalt, a baix, esquerra i dreta. Per a això utilitzarem vectors de quatre números i assignarem una posició a cada paraula. El nostre vector de quatre elements estarà format per zeros, excepte en la posició que hem assignat a cada paraula, on posarem un (Figura 2).
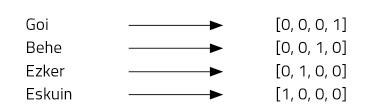
Aquest tipus de representació és molt simple i distingeix bé cada paraula, però té alguns inconvenients. Per exemple, tots sabem que les paraules a dalt i a baix són antònims. Els vectors de totes dues paraules demostren aquesta relació? No. L'ús de “one-hot vector” no permet imaginar relacions entre paraules. Un altre problema: el basc, per exemple, té unes 37 mil paraules [2]. Per a representar-les necessitaríem vectors de 37 mil dimensions! No sembla, per tant, una idea molt bona.
Word2Vec
És una idea atractiva utilitzar vectors per a representar paraules, ja que les xarxes neuronals treballen bé amb vectors. Però hem de millorar els vectors one-hot. Així ho van pensar Mikolov i els seus companys quan van inventar la tècnica Word2Vec [3]. Mitjançant aquesta tècnica s'obtenen representacions molt interessants de les paraules per:
1. Les paraules es poden representar mitjançant petits vectors.

2. Es poden representar relacions semàntiques entre paraules.
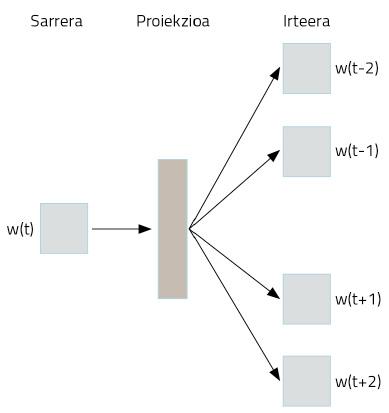
Com s'aconsegueix? Utilització estranya de xarxes neuronals. Suposem que prenem com a text tota la Wikipedia en basca. En ella apareixeran la majoria de les paraules en basca, en frases ben estructurades. Prendrem les paraules d'aquestes frases i codificarem one-hot vector mitjançant una representació simple. Ara ve el truc. Prendrem una paraula per a passar a una xarxa neuronal, l'objectiu de la qual és inventar les dues paraules que estan per davant i per darrere d'aquesta paraula. És a dir, entrenarem la xarxa neuronal per a endevinar el seu context amb una paraula, tal com es mostra en la Figura 3.
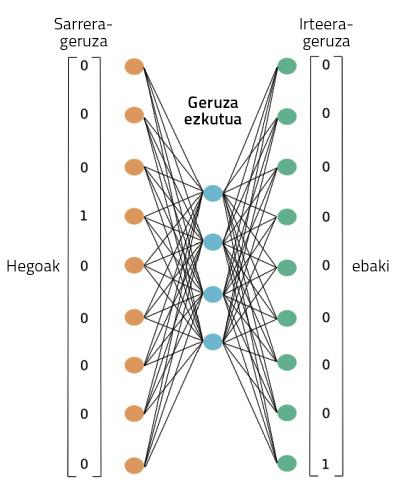
En la figura 4 es pot observar la xarxa neuronal utilitzada per a realitzar aquest entrenament. Processarà el text complet de la nostra Wikipedia en basca, tal com es mostra. A través d'una paraula, treballarà en aquest entrenament la capacitat d'endevinar el seu context. Al principi, la paraula context no encertarà, per la qual cosa cometrà grans errors. Però aquests errors s'utilitzen per a entrenar la xarxa. Així, la xarxa reduirà els seus errors d'invenció a través de l'observació de textos de milions de paraules.
Durant aquest procés, no obstant això, on estan les representacions de les paraules apreses? En la figura 4, en la casella que hem representat com a projecció. Potser per a entendre-ho millor, hem de mirar la figura 5. En ella es pot observar l'estructura més precisa de la xarxa neuronal en un cas en el qual només s'han pres dues paraules: una d'entrada i una altra de sortida. Una vegada finalitzat el procés d'entrenament, per a obtenir la representació d'una paraula n'hi ha prou amb passar aquesta paraula a la xarxa neuronal que acabem d'entrenar i prendre activacions ocultes de capa. Igual que les neurones dels nostres cervells, les neurones artificials també s'activen de manera diferent segons diferents estímuls. Doncs bé, les activacions que s'obtenen per a una paraula diferent seran la representació adequada d'aquesta paraula. No és sorprenent?
En definitiva, la xarxa neuronal que hem entrenat per a fer una tasca concreta ha après de manera automàtica algunes representacions numèriques de les paraules. I aquestes representacions són molt poderoses.
Jugant amb les paraules
Les activacions d'aquestes neurones ocultes són números. Per tant, col·locant 300 neurones en aquesta capa, obtindrem un vector de 300 números per a qualsevol paraula. Tenint en compte que en la representació d'One-hot vector necessitàvem més de 37 mil números, hem guanyat molt, no? Però això no és el millor. Aquests nous vectors de paraules tenen propietats gairebé màgiques. Jugarem amb ells, us quedeu oberts!
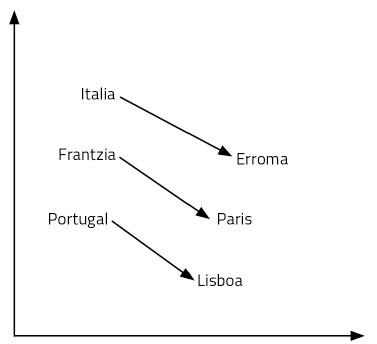
Comencem amb una pregunta: El que per a Itàlia és Roma, què és per a França? La teva resposta serà París. Per què? Perquè has vist país i capital en la relació Itàlia-Roma. Utilitzant el seu significat, ha fet aquest raonament. Així que has pensat quina és la capital de França: París. Per a trobar la resposta a la pregunta ha estat necessari manejar el llenguatge i els conceptes. Sembla un procés bastant complex.
Els vectors de paraules que acabem d'aprendre ens permeten respondre amb facilitat a aquesta mena de preguntes. En aquest cas, n'hi ha prou amb realitzar l'operació Itàlia – Roma + França. És a dir, al vector Itàlia li restem el vector Roma i després li afegim el vector França. I sí, el resultat és el vector París! Un altre exemple: Rei – home + dona = regna. Al·lucinant, no?
Com és possible? És així que afegir i eliminar vectors equival a raonar? Les representacions de les paraules que hem après són només punts d'un espai de 300 dimensions. Pensem en dues dimensions per a facilitar la seva visualització. En la figura 6 es representen alguns països i capitals en un pla de 2 dimensions. Com es pot observar, els països apareixen a prop, fins i tot les capitals, que formen part d'una categoria semàntica d'aquestes característiques. Però a més, la distància entre un país i la seva capital és igual per a tots els parells de capitals de país. Per això funcionen les nostres sumes i restes. Això mateix passa amb totes les paraules d'una llengua, però en un espai de 300 dimensions. Finalment, les relacions entre paraules, el seu significat i matisos són propietats geomètriques.
Cal tenir en compte que ningú ha dissenyat aquest espai semàntic que formen aquestes representacions de les paraules. Una xarxa neuronal ha après per si mateixa, una xarxa neuronal que s'ha entrenat per a inventar el seu context amb una paraula. És sorprenent pensar com una complexa representació és apresa per una xarxa que entrenem per a aprendre una tasca senzilla. Però així succeeix.
Per a acabar
La representació de les paraules mitjançant xarxes neuronals és la base del LNP actual. Per exemple, les xarxes complexes utilitzades en la traducció automàtica consideren aquests vectors de paraules com a introducció. Prendre vectors en basc i crear vectors en anglès, per exemple. En aquests processos s'ha observat que les propietats geomètriques entre paraules apreses en diferents llengües són molt similars. És a dir, les posicions relatives dels vectors king, man, woman i queen en anglès són pràcticament iguals als vectors rei, home, dona i reina en basca. Investigadors del Grup Ixa de la UPV, Elhuyar i Vicomtech, entre altres, estan estudiant aquestes vies i proposant tècniques innovadores de traducció.
Altres investigadors han demostrat que en les propietats geomètriques dels vectors es poden detectar tendències sexistes en la nostra llengua. Així, s'han proposat tècniques per a eliminar les tendències sexistes d'aquestes paraules perquè les màquines no repeteixin els nostres errors [5].
Tots aquests treballs canvien radicalment la nostra visió de la relació entre paraules i números. Tingues en compte que les nostres neurones treballen amb la tensió elèctrica. Amb números, d'alguna manera. Els nostres records, sentiments, llenguatge i raonament estan presents en els desplaçaments dels electrons entre neurones. Igual que ocorre amb les xarxes neuronals artificials, no parlo, sense adonar-me, operant amb un munt de números? No serà el nostre altre idioma?
Bibliografia
Treball presentat als premis CAF-Elhuyar.

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia

