

Language of numbers
2018/11/30 Azkune Galparsoro, Gorka - Ikertzailea eta irakasleaEuskal Herriko Unibertsitateko Informatika Fakultatea Iturria: Elhuyar aldizkaria

Human intelligence is very complex. So complex that we have not yet broken your skin. However, it is clear that one of the pillars of this intelligence is language. Language has allowed us to express complex concepts, shape ideas and transmit them to our peers, structure rich cultures and leave a mark on the next generations.
Given the importance of language in our mind, it has become a fundamental subject of research in the field of artificial intelligence. We call it natural language processing (LNP) and many of us can see it in more applications than we think: The LNP is used in automatic translators to identify spam messages and rank the comment of a product we purchased on Amazon.
In recent years the revolution of artificial neural networks has also reached the scope of the LNP, with spectacular practical conclusions [1]. But not only that: it has shown us interesting clues about how words and numbers relate.
Word representation for machines
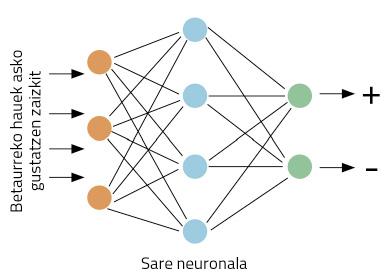
Suppose we are marketing directors of a glasses company. We have launched new glasses and we want to collect the opinions of buyers. For this we have come up with using the social network Twitter. We will create the hashtag that bears the name of our new glasses to know what our customers write about the glasses. The problem is that, as our company sells worldwide, we expect many tweets. So you can't read all the tweets! We would like all this work done by the computer.
We are going to concretize the work better: taking a bird, our computer must decide if a positive or negative opinion is given about our glasses. Let's start working. These types of problems are suitable for neural networks. The idea is simple: it teaches the neural network several tweets, indicating whether they are positive or negative; through the visualization of examples, the network will learn to distinguish between positive and negative (Figure 1).
But we have another problem: neural networks work with numbers, not words. How do we represent words with numbers? A lot of work has been done in the NPL world, which makes there many forms of word representation. The simplest idea is the so-called one-hot vector.
Imagine four words: top, bottom, left and right. For this we will use vectors of four numbers and assign a position to each word. Our four-element vector will be formed by zeros, except in the position we have assigned to each word, where we will put one (Figure 2).
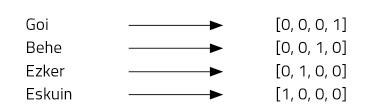
This type of representation is very simple and distinguishes each word well, but it has some drawbacks. For example, we all know that the words above and below are antonyms. Do the vectors of both words demonstrate this relationship? No. The use of “one-hot vector” does not allow to imagine relationships between words. Another problem: Basque, for example, has about 37,000 words [2]. To represent them we would need vectors of 37 thousand dimensions! It does not seem, therefore, a very good idea.
Word2Vec
It is an attractive idea to use vectors to represent words, as neural networks work well with vectors. But we have to improve the one-hot vectors. Mikolov and his colleagues thought so when they invented the Word2Vec technique [3]. This technique provides very interesting representations of words by:
1. Words can be represented by small vectors.

2. Semantic relationships between words can be represented.
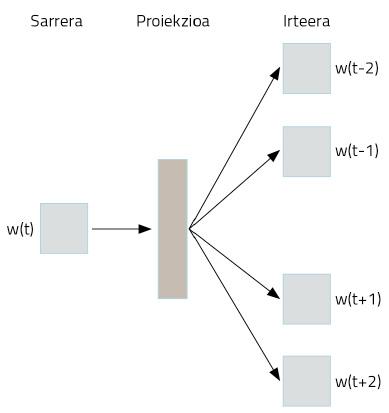
How do you get it? Strange use of neural networks. Suppose we take as text all Wikipedia in Basque. Most words will appear in Basque, in well-structured phrases. We will take the words of these phrases and encode one-hot vector by a simple representation. Now comes the trick. We will take a word to move to a neural network, whose goal is to invent the two words that are ahead and behind that word. That is, we will train the neural network to guess its context with a word, as shown in Figure 3.
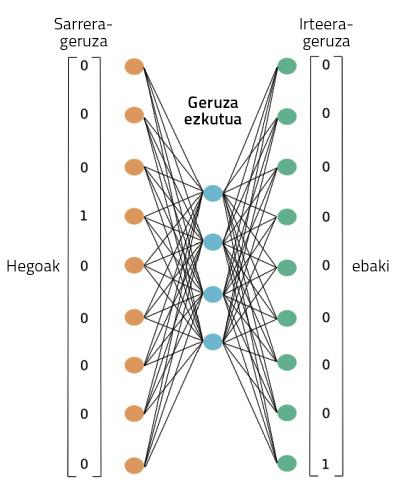
Figure 4 shows the neuronal network used to perform this training. It will process the full text of our Wikipedia in Basque, as shown. Through a word, you will work on this training the ability to guess your context. At first, the word context will not succeed, so it will make big mistakes. But these errors are used to train the network. Thus, the network will reduce its invention errors through the observation of texts of millions of words.
During this process, however, where are the representations of the learned words? In figure 4, in the box that we have represented as projection. Perhaps to understand it better, we have to look at figure 5. It shows the most precise structure of the neural network in a case in which only two words have been taken: one input and the other output. Once the training process is finished, to obtain the representation of a word, it is enough to pass that word to the neural network that we have just trained and take hidden layer activations. Like neurons in our brains, artificial neurons are also activated differently according to different stimuli. Well, the activations that are obtained for a different word will be the proper representation of that word. Isn't it surprising?
In short, the neural network we have trained to perform a specific task has automatically learned some numerical representations of words. And these representations are very powerful.
Playing with words
The activations of these hidden neurons are numbers. Therefore, by placing 300 neurons in this layer, we will get a vector of 300 numbers for any word. Considering that in the representation of One-hot vector we needed more than 37 thousand numbers, we won a lot, right? But that's not the best. These new word vectors have almost magical properties. Let's play with them, you stay open!
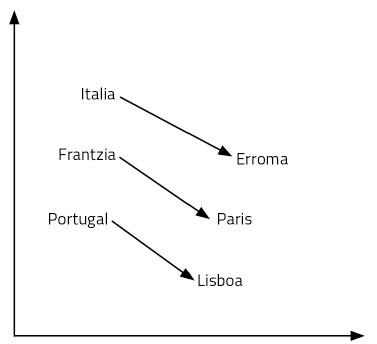
Let's start with a question: What for Italy is Rome, what is it for France? Your answer will be Paris. Why? Because you have seen country and capital in the Italy-Rome relationship. Using its meaning, it has made that reasoning. So you thought about the capital of France: Paris. To find the answer to the question it has been necessary to handle language and concepts. It seems a fairly complex process.
The word vectors we just learned allow us to easily answer these kinds of questions. In this case, just carry out the operation Italy – Rome + France. That is, we subtract the Rome vector from the Italy vector and then add the France vector. And yes, the result is the Paris vector! Another example: King – man + woman = queen. Amazing, right?
How is it possible? Is it so that adding and removing vectors amounts to reason? The representations of the words we have learned are only points of a space of 300 dimensions. Let's think of two dimensions to facilitate its visualization. Figure 6 shows some countries and capitals on a 2-dimensional plane. As can be seen, countries appear nearby, even capitals, which are part of a semantic category of these characteristics. But also, the distance between a country and its capital is equal for all pairs of country capitals. That's why our sums and rests work. That same thing happens with all the words of a language, but in a space of 300 dimensions. Finally, the relationships between words, their meaning and nuances are geometric properties.
It must be borne in mind that no one has designed that semantic space that forms those representations of words. A neural network has learned by itself, a neuronal network that has been trained to invent its context with a word. It is surprising to think how a complex representation is learned by a network that we train to learn a simple task. But so it happens.
To finish
The representation of words by neural networks is the basis of the current NPL. For example, the complex networks used in machine translation consider these word vectors as an introduction. Take vectors in Basque and create vectors in English, for example. In these processes it has been observed that the geometric properties between words learned in different languages are very similar. That is, the relative positions of the king, man, woman and queen vectors in English are practically equal to the king, man, woman and queen vectors in Basque. Researchers from the Ixa Group of the UPV, Elhuyar and Vicomtech, among others, are studying these ways and proposing innovative translation techniques.
Other researchers have shown that the geometric properties of vectors can detect sexist trends in our language. Thus, techniques have been proposed to eliminate sexist tendencies of these words so that machines do not repeat our mistakes [5].
All these works radically change our vision of the relationship between words and numbers. Keep in mind that our neurons work with electrical voltage. With numbers, somehow. Our memories, feelings, language and reasoning are present in the displacements of electrons between neurons. As with artificial neural networks, do I not speak, without realizing it, operating with a lot of numbers? Will it not be our other language?
Bibliography
Work presented to the CAF-Elhuyar awards.

Gai honi buruzko eduki gehiago
Elhuyarrek garatutako teknologia

